4. 아키텍처
4.1 MySQL 엔진 아키텍처
MySQL 서버는 머리 역할을 하는 MySQL 엔진과 손발 역할을 담당하는 스토리지 엔진으로 구분됨
손과 발을 담당하는 스토리지 엔진은 핸들러 API를 만족하면 누구던 스토리지 엔진을 구현해서 MySQL 서버에 추가해요 사용 가능
이번 장에서 MySQL 엔진과 기본으로 제공되는 InnoDB 스토리지 엔진, MyISAM 스토리지 엔진을 구분해서 학습
4.1.1 MySQL의 전체 구조

4.1.1.1 MySQL 엔진
클라이언트로부터의 접속 및 쿼리 요청을 처리하는 커넥션 핸들러와 SQL 파서 및 전처리기, 쿼리의 최적화된 실행을 위한 옵티마이저가 중심을 이룸
4.1.1.2 스토리지 엔진
MySQL 엔진은 요처된 SQL 문장을 분석하거나 최적화하는 등 두뇌에 해당하는 처리를 수행
스토리지 엔진은 실제 데이터를 디스크 스토리지에 저장하거나 디스크 스토리지로부터 데이터를 읽어오는 부분은 스토리지 엔진이 전담
MySQL 엔진은 하나지만 스토리지 엔진은 여러 개를 동시에 사용할 수 있음
4.1.1.3 핸들러 API
MySQL 엔진의 쿼리 실행기에서 데이터를 쓰거나 읽어야할 때 각 스토리지 엔진에 쓰기 또는 읽기를 요청하는데, 이를 핸들러 요청이라고함
여기서 사용되는 API를 핸들러 API 라고함
InnoDB 스토리지 엔진 또한 이 핸들러 API를 이용해 MySQL엔진과 데이터를 주고 받음
4.1.2 MySQL 스레딩 구조
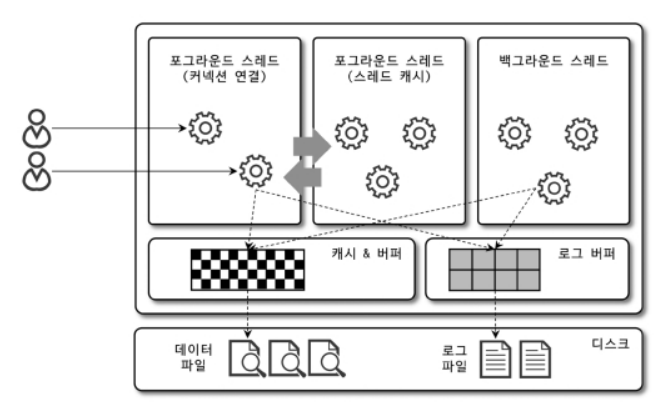
MySQL 서버는 프로세스 기반이 아닌 스레드 기반으로 작동하며 크게 포그라운드 스레드와 백그라운드 스레드로 구분함
4.1.2.1 포그라운드 스레드(클라이언트 스레드)
포그라운드 스레드는 최소한 MySQL 서버에 접속된 클라이언트 수 만큼 존재하며 주로 각 클라이언트 사용자가 요청하는 쿼리 문장을 처리
커넥션을 종료하면 스레드는 스레드 캐시로 돌아감. 스레드 캐시에 일정 개수 이상의 대기 중인 스레드가 있다면 넣지 않고 종료시킴. thread_cache_size 시스템 변수로 설정함
포그라운드 스레드는 데이터를 MySQL의 데이터 버퍼나 캐시로부터 가져오지만 버퍼나 캐시에 없는 경우 직접 디스크의 데이터나 인덱스 파일로부터 데이터를 읽어옴
MyISAM 테이블은 디스크 쓰기 작업까지 포그라운드 스레드가 처리함
InnoDB 테이블은 데이터 버퍼나 캐시까지만 포그라운드 스레드가 처리하고 나머지 버퍼로부터 디스크까지 기록하는 작업은 백그라운드 스레드가 처리
4.1.2.2 백그라운드 스레드
MyISAM은 해당 사항이 별로 없지만 InnoDB는 아래와 같이 여러 가지 작업이 백그라운드로 처리됨
- 인서트 버퍼를 병합하는 스레드
- 로그를 디스크로 기록하는 스레드
- InnoDB 버퍼 풀의 데이터를 디스크에 기록하는 스레드
- 데이터를 버퍼로 읽어 오는 스레드
- 잠금이나 데드락을 모니터링하는 스레드
그렇기때문에, MyISAM은 사용자가 쓰기 작업까지 한번에 작업하고, 쓰기 버퍼링 기능을 사용할 수 없음
InnoDB에서는 INSERT, UPDATE, DELETE 쿼리로 데이터가 변경되는 경우 데이터가 디스크의 데이터 파일로 완전히 저장될떄까지 기다리지 않아도 됨
4.1.3 메모리 할당 및 사용 구조

MySQL에서 사용된느 메모리 공간은 글로벌 메모리 영역과 롴러 메모리 영역으로 구분됨
글로벌 메모리 영역의 메모리 공간은 MySQL 서버가 시작되면서 운영체제로부터 할당됨
MySQL의 시스템 변수로 설정해 둔 만큼 운영체제로부터 메모리를 할당받는다고 생각해도 됨
글로벌 메모리 영역과 로컬 메모리 영역은 MySQL 서버 내의 스레드의 공유 여부에 따라 구분됨
4.1.3.1 글로벌 메모리 영역
스레드가 10개든 100개든 InnoDB 버퍼 풀 같은 메모리공간은 1개만 존재하고 모든 스레드가 이것을 공유해서 사용함
- 테이블 캐시
- InnoDB 버퍼 풀
- InnoDB 어댑티브 해시 인덱스
- InnoDB 리두 로그 버퍼
4.1.3.2 로컬 메모리 영역
MySQL 서버 상에 존재하는 클라이언트 스레드가 쿼리를 처리하는 데 사용하는 메모리 영역
- 정렬 버퍼
- 조인 버퍼
- 바이너리 로그 캐시
- 네트워크 버퍼
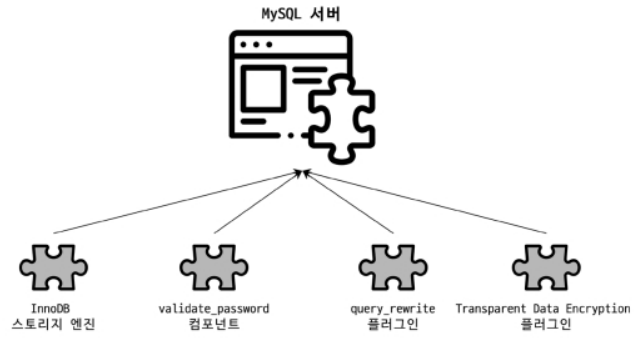
4.1.4 플러그인 스토리지 엔진 모델
상태 변수 중에서 Handler_로 시작하는 변수는 MySQL엔진이 각 스토리지 엔진에게 보낸 명령의 횟수를 의미하는 변수
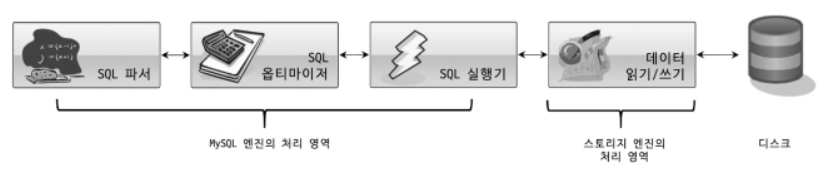
MySQL에서 MyISAM이나 InnoDB와 같이 다른 스토리지 엔진을 사용하는 테이블에 대해 쿼리를 실행하더라도 MySQL의 처리 내용은 대부분 동일하며 데이터 읽기/쓰기 영역의 처리만 차이가 있음
MySQL 서버에서는 스토리지 엔진뿐만 아니라 다양한 기능을 플러그인 형태로 지원함
인증이나 전문 검색 파서 또는 쿼리 재작성과 같은 플러그인 이 있고 비밀번호 검증과 커넥션 제어 등 다양한 플러그인이 존재
4.1.5 컨포넌트
MySQL 8.0부터는 기존의 플러그인 아키텍처를 대체하기 위해 컴포넌트 아키텍처가 지원됨
MySQL 서버의 플러그인은 아래와 같은 단점이 있는데 컴포넌트는 이 단점들을 보완되어 구현됐음
- 플러그인은 오직 MySQL 서버와 인터페이스할 수 있고, 플러그인끼리는 통신할 수 없음
- 플러그인은 MySQL 서버의 변수나 함수를 직접 호출하기 때문에 안전하지 않음 (캡슐화 안 됨)
- 플러그인은 상호 의존 관계를 설정할 수 없어 초기화가 어려움
4.1.6 쿼리 실행 구조

4.1.6.1 쿼리 파서
사용자 요청으로 들어온 문장을 토큰(MySQL이 인식할 수 있는 단위)으로 분리해 트리 형태의 구조로 만들어내는 작업을 의미
쿼리의 문법 옹류는 이곳에서 발견함
4.1.6.2 전처리기
문법 오류가 아닌 실제 존재하지 않거나 권한상 사용할 수 없는 개체의 토큰이 이 단계에서 걸러짐
4.1.6.3 옵티마이저
사용자의 요청의 쿼리 문장을 저렴한 비용으로 가장 빠르게 처리할지를 결정하는 역할
DBMS의 두뇌
어떻게하면 옵티마이저가 더 나은 선택을 할 수 있게 유도하는가를 학습
4.1.6.4 실행 엔진
옵티마이저가 두뇌라면 실행 엔진과 핸들러는 손과 발로 비유
옵티마이저는 회사 경영진, 실행 엔진은 중간 관리자, 핸들러는 각 업무의 실무자
ex) 옵티마이저가 GROUP BY를 처리하기 위해 임시 테이블을 사용하기로 결정
- 실행 엔진이 핸들러에게 임시 테이블을 만들어달라고 요청
- 다시 실행 엔진은 WHERE 절에 일치하는 레코드를 읽어오라고 핸들러에게 요청
- 읽어온 레코드들을 1번에서 준비한 임시 테이블로 저장하라고 다시 핸들러에게 요청
- 데이터가 준비된 임시 테이블에서 필요한 방식으로 데이터를 읽어 오라고 핸들러에게 다시 요청
- 최종적으로 실행 엔진은 결과를 사용자나 다른 모듈로 넘김
결론적으로 실행 엔진은 만들어진 계획대로 각 핸들러에게 요청해서 받은 결과를 또 다른 핸들러 요청의 입력으로 연결하는 역할을 수행
4.1.6.5 핸들러(스토리지 엔진)
핸들러는 MySQL 서버의 가장 밑단에서 MySQL 실행 엔진의 요청에 따라 데이터를 디스크로 저장하고 읽어오는 역할을 담당
핸들러는 스토리지 엔진을 의미하고 MyISAM 테이블을 조직하는 경우에는 핸들러가 MyISAM 스토리지 엔진이 되고, InnoDB 테이블을 조작하는 경우에는 InnoDB 스토리지 엔진이 됨
4.1.7 복제
16장 복제에서 학습
4.1.8 쿼리 캐시
쿼리의 결과를 캐시에 저장하는 기능이지만 변경된 테이블을 모두 삭제하여야하므로 동시 처리 성능 저하를 유발함
MySQL 8.0 부터 제거됨
4.1.9 스레드 풀
MySQL 엔터프라이즈는 스레드 풀 기능을 제공하지만 커뮤니티 에디션은 지원하지 않음
아래에서 언급하는 스레드 풀은 엔터프라이즈에서 제공하는 스레드 풀이 아닌 Percona Server에서 제공하는 스레드 풀 기능
플러그인 형태로 작동하게 구현되어있으므로 플러그인 라이브러리를 MySQL 커뮤니티 에디션에 설치해서 사용하면 됨
스레드 풀은 내부적으로 사용자의 요청을 처리하는 스레드 개수를 줄여서 동시 처리되는 요청이 많아도 MySQL 서버의 CPU가 제한된 개수의 스레드 처리에만 집중할 수 있게 하여 서버의 자우너 소모를 줄이는 것이 목적
스레드 풀이 실제 서비스에서 눈에 띄는 성능 향상을 보여준 경우는 드뭄
Percona Server의 스레드풀은 CPU 코어의 개수와 스레드풀 개수를 맞추는 것이 CPU 프로세서 친화도를 높이는데 좋음
MySQL 서버가 처리해야 할 요청이 생기면 스레드 풀로 처리를 이관하는데 스레드 풀이 실행 중이면 추가적으로 처리함
이 값이 너무 크다면 스케줄링해야 할 스레드가 많아져 스레드 풀이 비효율적으로 작동할 수도 있음
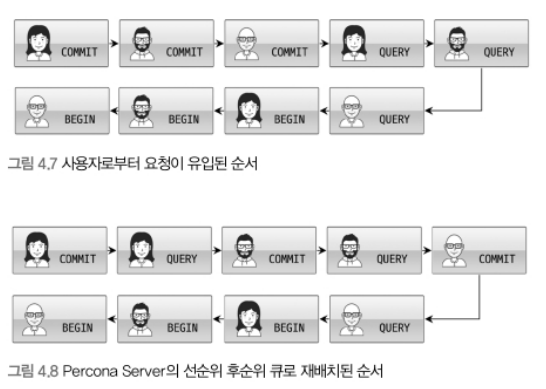
그림 4.7 - 사용자 요청이 유입된 순서
→ 사용자 3명이 트랜잭션(BEGIN → QUERY/COMMIT)을 보내면,
스레드 풀은 유입된 순서 그대로 처리한다.
→ 일반적인 처리 방식이며, 처리 효율이 떨어질 수 있음.
그림 4.8 - Percona Server의 우선순위 큐 기반 재정렬
→ Percona는 스레드 풀 내부에서 요청을 재배치함.
→ 이미 트랜잭션이 시작된 쿼리(QUERY, COMMIT)를 선순위 큐로 우선 처리.
→ 아직 시작되지 않은 트랜잭션(BEGIN)은 후순위 큐로 밀려나 대기.
→ 이렇게 하면 락을 오래 잡고 있는 쿼리를 빨리 해소시켜
전체 처리 성능(동시성, 응답속도)이 향상됨.
4.1.10 트랜잭션 지원 메타데이터
MySQL 8.0 버전부터는 기존 파일 기반의 데이터 저장 방식에서 InnoDB의 테이블에 저장하도록 변경하여 메타데이터의 트랜잭션을 보장함
MySQL 서버가 작동하기 위해 기본적으로 필요한 테이블을 시스템 테이블이라하고 이것 또한 MySQL 8.0 버전부터는 InnoDB 스토리지 엔진을 사용하도록 개선됨
시스템 테이블과 데이터 딕셔너리 정보를 모두 모아 mysql DB에 저장함
mysql DB는 통째로 mysql.ibd라는 이름의 테이블스페이스에 저장함
그래서 MySQL 서버의 데이터 디렉터리에 존재하는 mysql.ibd라는 파일은 다른 *.ibd 파일과 함께 주의해야함
4.2 InnoDB 스토리지 엔진 아키텍처
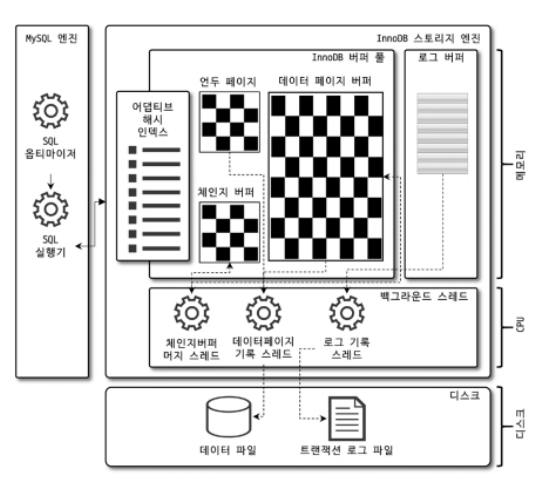
InnoDB는 MySQL에서 사용할 수 있는 스토리지 엔진 중 거의 유일하게 레코드 기반의 잠금(행 단위 잠금)을 제공하여 높은 동시성 처리가 가능함
4.2.1 프라이머리 키에 의한 클러스터링
InnoDB의 모든 테이블은 기본적으로 프라이머리 키를 기준으로 클러스터링되어 저장됨
즉 프라이머리 키 값의 순서대로 디스크에 저장되며 모든 세컨더리 인덱스는 레코드의 주소 대신 프라이머리 키의 값을 논리적인 주소로 사용함
클러스터링 인덱스(InnoDB)는
- 프라이머리 키를 기준으로 정렬된 B+ Tree
- 리프 노드에 "해당 row의 모든 컬럼 값"이 저장됨 (== 데이터 자체)
그래서 "인덱스가 곧 데이터"라고 부름
MyISAM은
- 인덱스는 프라이머리 키 값 + 데이터 위치(ROWID)만 저장
- 실제 데이터는 다른 곳에 따로 저장됨
4.2.2 외래 키 지원
MyISAM이나 MEMORY 테이블에서는 외래키가 존재하지 않음
만약 외래 키를 연관된 것 때문에 삭제하지 못한다면 foreign_key_checks 시스템 변수를 OFF 로 설정하고 삭제하면 일시적으로 해결 가능
SET foreign_key_checks=0FF;
-- 작 업 실 행
SET foreign_key_checks=ON;4.2.3 MVCC (Multi Version Concurrency Control)
| 항목 | Query Cache | InnoDB Buffer Pool |
|---|---|---|
| 캐싱 대상 | 쿼리 결과 (Result Set) | 디스크의 데이터 페이지 (기본 16KB) |
| 캐싱 단위 | SQL 쿼리 1개 → 결과값 1개 | 데이터 블록 1개 → 여러 레코드 포함 |
| 변경 대응 방식 | 관련 테이블 변경 시 전체 무효화 | 버퍼에서 직접 수정 후 flush 또는 로그 기반 복구 |
| 히트 조건 | 동일한 SQL 텍스트 (공백, 대소문자까지 같아야 함) | 동일한 페이지에 접근할 경우 |
| 무효화 처리 | 변경 시 전체 캐시 제거 | 필요 시 flush (디스크 반영) |
| 쓰기 처리 가능 여부 | ❌ 읽기 전용 | ✅ 읽기 + 쓰기 모두 가능 |
| 복구 지원 | ❌ (데이터 무결성과 무관) | ✅ Redo/Undo 로그와 연계된 트랜잭션 복구 지원 |
| 병목 가능성 | 높음 (락 경쟁, 전역 캐시) | 낮음 (LRU 등 최적화 구조) |
| MySQL 8.0에서의 상태 | ❌ 제거됨 | ✅ 계속 유지 및 강화됨 |
| 적합한 용도 | 정적 페이지, 변경 거의 없는 데이터 | 대부분의 OLTP/OLAP 환경에서 기본 필수 요소 |
1. MVCC와 Undo 로그의 관계 (MySQL InnoDB 기준)
- InnoDB는 MVCC를 구현하기 위해 Undo 로그를 사용함
- 데이터 변경 시, 변경 전 데이터를 Undo 로그에 저장함
- 다른 트랜잭션이 동일한 데이터를 조회할 경우, Undo 로그에 저장된 예전 데이터를 기반으로 과거 버전을 보여줌
- 즉, Undo 로그는 MVCC에서 “스냅샷 일관성(Read View)“을 제공하는 핵심 메커니즘
- Undo 로그가 없다면, 다른 트랜잭션이 과거 데이터를 읽을 수 없어 MVCC를 구현할 수 없음
2. 다른 데이터베이스에서는 Undo 로그 없이 어떻게 가능한가?
- 다른 DBMS는 Undo 로그 없이도 MVCC를 구현하지만, 데이터 버전 관리 방식이 다름
- PostgreSQL:
- Undo 로그가 없고, 테이블 자체가 다중 버전(버전 체인)을 유지
- 각 레코드는 xmin, xmax 등 트랜잭션 정보를 포함하며, 트랜잭션 ID 기반으로 읽을 버전을 판별함
- 필요 없는 오래된 버전은 VACUUM 프로세스를 통해 정리함
- SQL Server:
- Snapshot Isolation에서 Undo 로그 대신 TempDB에 변경 전 데이터를 저장
- 이를 통해 읽기 트랜잭션은 COMMIT된 상태의 과거 데이터를 조회할 수 있음
- Oracle:
- Undo Segment를 사용하여 InnoDB처럼 Undo 로그 기반으로 MVCC를 구현
Undo 로그는 MVCC를 구현하는 한 가지 방식일 뿐이며, DBMS마다 데이터 버전을 보관하는 구조는 다양함
4.2.5 자동 데드락 감지
- InnoDB는 데드락 감지 전용 스레드를 통해 주기적으로 데드락 여부를 확인
- 트랜잭션 간 락 대기 목록을 Wait-for 그래프로 구성
- 그래프에서 순환(Cycle)이 생기면 데드락으로 판단
- 데드락 발생 시 자동으로 트랜잭션 중 하나를 선택해 강제로 ROLLBACK
관련 시스템 변수
| 변수명 | 설명 |
|---|---|
innodb_deadlock_detect |
ON이면 자동 감지 활성화, OFF면 감지 비활성화 |
innodb_lock_wait_timeout |
트랜잭션이 락을 대기할 수 있는 최대 시간 (초 단위, 기본값 50초) |
주의 사항
- 트랜잭션 수가 많을수록 감지 스레드가 과부하 가능성 있음
- 락 경합이 심한 시스템에서는 감지 자체가 병목 요인
- Google 등에서는
innodb_deadlock_detect=OFF설정 후lock_wait_timeout을 낮게 설정해 운영
DBMS별 데드락 감지 방식 비교
| DBMS | 감지 방식 | 감지 시점 | 처리 방식 |
|---|---|---|---|
| MySQL/InnoDB | 감지 스레드가 주기적으로 Wait-for 그래프 순회 | 주기적 감지 | 트랜잭션 중 하나 ROLLBACK |
| Oracle | 트랜잭션이 락 요청 시 데드락 여부 즉시 검사 | 요청 시점 감지 | 트랜잭션 중 하나 ROLLBACK |
| SQL Server | 데드락 모니터 스레드가 주기적으로 감지 | 주기적 감지 | 희생자(victim) 트랜잭션 선택 후 ROLLBACK |
| PostgreSQL | 트랜잭션이 락 요청 시 내부 그래프 분석 | 요청 시점 감지 | 트랜잭션 중 하나 ROLLBACK |
4.2.6 자동화된 장애 복구
- InnoDB는 트랜잭션 중간에 장애가 발생했을 때를 대비해 자동 복구 기능을 제공
- MySQL 서버 시작 시 디스크에 일부만 기록된 상태(Partial Write)나 미완료 트랜잭션을 자동 복구
- Redo 로그와 Undo 로그를 통해 데이터 복구
- 대부분의 장애는 InnoDB가 자동으로 복구
복구 실패 시
- 디스크 손상 등으로 InnoDB가 자동 복구하지 못할 경우 수동 개입 필요
- 이때 사용하는 시스템 변수는
innodb_force_recovery - MySQL이 완전히 부팅되지 않을 때 해당 옵션을 설정해 최소한의 상태로 기동
- 기동 후
mysqldump등으로 데이터 백업 후 새로운 인스턴스를 구성
innodb_force_recovery 단계별 설명
- 총 6단계가 있으며 숫자가 커질수록 데이터 정합성을 포기하고 강제 복구 시도
- 가능한 한 낮은 숫자부터 순차적으로 적용
innodb_force_recovery가 설정되면 SELECT 외의 쿼리는 수행 불가
| 단계 | 설명 |
|---|---|
| 1 (SRV_FORCE_IGNORE_CORRUPT) | 손상된 인덱스 페이지 무시하고 서버 기동 |
| 2 (SRV_FORCE_NO_BACKGROUND) | purge 스레드 중지. Undo 백그라운드 작업 비활성화 |
| 3 (SRV_FORCE_NO_TRX_UNDO) | 트랜잭션 Undo 로그 무시. 커밋되지 않은 데이터도 남아 있을 수 있음 |
| 4 (SRV_FORCE_NO_IBUF_MERGE) | Insert Buffer 병합 중단. 메타데이터 관련 손상 시 기동 가능성 높임 |
| 5 (SRV_FORCE_NO_UNDO_LOG_SCAN) | Undo 로그 스캔 생략. 트랜잭션 상태 무시하고 데이터 복구 |
| 6 (SRV_FORCE_NO_LOG_REDO) | Redo 로그 무시. 마지막 커밋 여부 고려하지 않고 데이터 적용 상태로 시작 |
실무 적용 방식
- MySQL 서버가 시작되지 않으면
innodb_force_recovery=1설정 후 기동 시도 - 실패 시 숫자를 높여가며 최대
6까지 순차적으로 설정 - 서버가 기동되면
mysqldump로 데이터를 백업 - 새로운 MySQL 인스턴스에서 백업 데이터를 복원해 복구 마무리
- 복구 이후에는 반드시
innodb_force_recovery설정을 제거한 후 재기동 필요
주의 사항
innodb_force_recovery는 일시적인 복구 목적에서만 사용- 설정된 상태에서는 INSERT, UPDATE, DELETE 등 데이터 변경 불가능
- 복구된 데이터는 정합성이 완전하지 않을 수 있어 확인 필요
- 가능하면 Redo 로그, 바이너리 로그 등으로 복원할 수 있는 구조를 사전에 준비하는 것이 바람직
4.2.7 InnoDB 버퍼 풀
4.2.7.1 버퍼 풀의 크기 설정
- InnoDB 버퍼 풀은 MySQL 스토리지 엔진에서 가장 핵심적인 메모리 공간
- 디스크에 있는 데이터나 인덱스를 미리 메모리에 적재해 디스크 접근 없이 처리할 수 있게 하는 캐시 역할
- 일반적으로 전체 물리 메모리의 70~80% 수준으로 설정
- 단순히 퍼센트로만 결정하지 말고 운영체제나 다른 애플리케이션이 사용할 메모리 공간을 고려해서 설정
- 서버 내에서 MySQL 이외의 프로그램이 거의 없으면 버퍼 풀 크기를 상대적으로 크게 설정
- 캐시 활용도가 높은 워크로드일수록 큰 크기의 버퍼 풀이 유리
- MySQL 5.7부터는 버퍼 풀 크기를 동적으로 조정 가능
innodb_buffer_pool_size시스템 변수로 설정- 동적 조정이 가능하지만, 변경 시점에 부하가 적은 시간에 수행 권장
- 버퍼 풀은 128MB 단위로 관리되며, 늘리거나 줄일 때에도 해당 단위로 조정
- 인스턴스를 나눠서 병렬 처리 효율을 높이는
innodb_buffer_pool_instances도 함께 설정 - 전체 버퍼 풀 크기가 1GB 이상이면 인스턴스를 여러 개로 나누는 것을 권장
- 인스턴스당 메모리 크기가 1GB 이상이 되도록 조정
- 버퍼 풀 설정 시 권장 예시
- 메모리 8GB → 버퍼 풀 4~6GB 설정
- 메모리 50GB → 버퍼 풀 30~40GB 설정
- 너무 크거나 작게 설정하지 말고 적절한 캐시 활용률을 고려해서 설정
- 실제로는 버퍼 풀 사이즈와 인스턴스 수를 같이 조정해야 병목 없이 효율적인 메모리 사용 가능
- 버퍼 풀 인스턴스가 많아지면 내부 잠금 충돌을 줄이고 동시 처리 성능 향상
- 설정 변경 후에는 MySQL 서버의 상태를
SHOW ENGINE INNODB STATUS나 퍼포먼스 스키마로 확인해서 캐시 적중률 등 모니터링 수행 필요
4.2.7.2 버퍼 풀의 구조
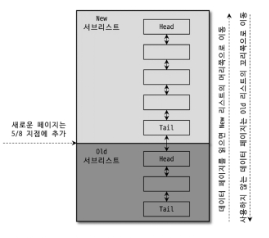
1. 버퍼 풀의 단위
- InnoDB 버퍼 풀은
innodb_page_size크기의 페이지 단위로 데이터와 인덱스를 캐싱 - 각 페이지는 특정 리스트에 포함되어 관리
2. 버퍼 풀의 리스트 구성
| 리스트 이름 | 설명 |
|---|---|
| LRU 리스트 | 자주 사용되는 페이지는 앞쪽, 오래된 페이지는 뒤쪽으로 이동하여 캐시 유지 |
| 플러시 리스트 | 디스크에 아직 반영되지 않은 변경된 페이지(Dirty Page)를 추적 |
| 프리 리스트 | 현재 사용되지 않는 빈 페이지들을 모아둔 공간 |
3. LRU 리스트의 내부 구조
- LRU 리스트는 Old 영역과 New 영역(MRU)으로 나뉨
- 새로 로딩된 페이지는 Old 리스트 중간에 삽입
- 자주 사용된 페이지는 New(MRU) 영역으로 승격
- 사용되지 않는 페이지는 LRU 리스트의 끝으로 밀려 제거 대상이 됨
4. 페이지 접근 및 유지 흐름
- 쿼리를 통해 데이터 페이지 요청 발생
- InnoDB는 해당 페이지가 버퍼 풀에 존재하는지 확인
- 없으면 디스크에서 읽어서 LRU 중간에 삽입
- 자주 접근되면 MRU 방향으로 승격
- 장시간 미사용되면 LRU 끝으로 이동되어 제거 대상
5. 플러시 리스트의 역할
- 변경된 페이지는 플러시 리스트에 등록되어 추적
- 디스크에 동기화되면 플러시 리스트에서 제거
- Checkpoint 또는 MySQL 종료 시점에 디스크로 기록
- Redo 로그에 먼저 기록한 후, 실제 페이지 변경 내용도 디스크에 반영
6. 프리 리스트의 역할
- 새로운 페이지 로딩 시, 사용 가능한 빈 페이지를 프리 리스트에서 할당
- 디스크에서 페이지를 읽어올 공간 확보에 사용
7. LRU 리스트 관리 목적
- 디스크 I/O를 최소화하고 캐시 효율을 높이기 위해 LRU 리스트를 유지
- 페이지가 자주 사용되면 더 오래 메모리에 유지
- 거의 사용되지 않으면 LRU 리스트의 끝으로 이동하여 제거됨
8. 요약 표
| 구성 요소 | 설명 |
|---|---|
| LRU 리스트 | 페이지 접근 빈도에 따라 위치 이동. Old와 MRU(New) 영역으로 분리 |
| 플러시 리스트 | Dirty Page를 디스크에 기록하기 전까지 관리 |
| 프리 리스트 | 빈 페이지 목록. 새 페이지 적재 시 사용 |
| MRU 영역 | 자주 사용하는 페이지가 유지되는 공간 |
| LRU 끝 | 제거 대상 페이지가 위치하는 공간 |
4.2.7.3 버퍼 풀과 리두 로그
1. 버퍼 풀과 리두 로그의 관계
- InnoDB는 데이터 변경 시 디스크에 바로 쓰지 않고 버퍼 풀에 먼저 반영
- 변경된 데이터는 동시에 리두 로그(Redo Log)에 기록
- 버퍼 풀은 성능 향상을 위한 캐시, 리두 로그는 장애 복구를 위한 복제 기록 영역
- 리두 로그에 기록된 후 일정 시점에서 디스크로 flush되며, 그 시점을 체크포인트라고 함
2. 페이지 종류
| 페이지 종류 | 설명 |
|---|---|
| 클린 페이지 (Clean Page) | 디스크에서 읽어와 변경되지 않은 페이지 |
| 더티 페이지 (Dirty Page) | 메모리에서 변경되었지만 아직 디스크에 기록되지 않은 페이지 |
- 더티 페이지는 리두 로그에 먼저 기록된 후 디스크에 반영됨
- 클린 페이지는 디스크와 동일 상태이므로 flush 불필요
3. 리두 로그 구조와 개념
- 리두 로그는 고정 크기의 파일들로 구성된 순환 구조
- LSN(Log Sequence Number): 리두 로그 내 각 엔트리의 고유 번호
- Checkpoint: 디스크에 flush된 가장 오래된 LSN 이후부터의 영역을 의미
- Checkpoint Age: 체크포인트부터 현재까지 사용된 리두 로그 크기
4. 리두 로그와 버퍼 풀의 상호작용
- 리두 로그 공간이 부족하면 더 이상 쓰기 불가능 → 체크포인트 발생 필요
- 체크포인트 발생 시 더티 페이지를 디스크에 flush하여 리두 로그 공간 확보
- 너무 잦은 체크포인트는 I/O 성능 저하를 유발하므로 리두 로그 공간 확보가 중요
5. 실전 예시 비교
1) InnoDB 버퍼 풀: 1000MB, 리두 로그: 100MB
- 리두 로그 공간 100MB → 평균 로그 엔트리 크기 4KB 기준 약 25600개 엔트리 저장 가능
- 더티 페이지 1개당 16KB 기준으로는 약 400MB 분량까지만 커버 가능
- 이 경우 나머지 600MB에 해당하는 데이터는 자주 체크포인트 발생 필요
2) InnoDB 버퍼 풀: 100MB, 리두 로그: 1000MB
- 리두 로그는 과하게 크고 공간 낭비
- 실질적인 성능 개선 효과는 미미
6. 권장 설정 기준
- 리두 로그의 총 용량은 버퍼 풀의 10~20% 정도 권장
- 예: 버퍼 풀 10GB → 리두 로그 1~2GB
- 버퍼 풀이 100MB 수준이라면 최소 100MB 이상의 리두 로그 확보 필요
- 지나치게 작은 리두 로그는 자주 체크포인트를 유발하고, 성능 저하의 원인이 될 수 있음
7. 결론
- 리두 로그와 버퍼 풀은 서로 밀접하게 연관되어 있음
- 리두 로그는 데이터 복구, 버퍼 풀은 캐시 및 성능 최적화를 위한 영역
- 버퍼 풀 크기와 리두 로그 크기의 균형을 고려해 설정하는 것이 필수
4.2.7.4 버퍼 풀 플러시(Buffer Pool Flush)
- 더티 페이지를 디스크에 동기화하는 작업을 플러시라고 정의
- MySQL 5.6까지는 플러시 기능이 부드럽게 처리되지 않아 디스크 폭주 등의 성능 문제가 발생
- MySQL 5.7 이후부터는 대부분의 환경에서 자동 플러시가 안정적으로 수행
- InnoDB는 아직 디스크에 반영되지 않은 더티 페이지를 성능상 악영향 없이 백그라운드에서 동기화하기 위해 플러시 기능을 자동으로 실행
플러시의 종류
- 플러시 리스트(Flush_list) 플러시
- LRU 리스트(LRU_list) 플러시
4.2.7.4.1 플러시 리스트 플러시
- 오래된 리두 로그 공간 확보를 위해 더티 페이지를 디스크로 반영
- 더티 페이지가 디스크에 쓰이기 전에는 해당 리두 로그 공간을 재사용할 수 없음
- 플러시 리스트는 이러한 더티 페이지를 순차적으로 디스크에 기록
- 한 번에 너무 많은 더티 페이지를 flush하면 성능이 저하되므로 제한 필요
관련 시스템 변수
innodb_page_cleaners: 버퍼 풀 인스턴스마다 병렬로 실행되는 클리너 스레드 개수 조절innodb_max_dirty_pages_pct: 전체 버퍼 풀 중 더티 페이지 비율의 상한값innodb_max_dirty_pages_pct_lwm: 더티 페이지 비율이 해당 수치를 초과하면 플러시 유도innodb_io_capacity,innodb_io_capacity_max: 디스크 I/O 처리량 설정값innodb_flush_neighbors: 플러시 시 인접한 페이지를 함께 쓰도록 설정innodb_adaptive_flushing,innodb_adaptive_flushing_lwm: 더티 페이지 증가 패턴을 분석해 알맞은 시점에 플러시 트리거
플러시 최적화 전략
innodb_max_dirty_pages_pct를 너무 높게 설정하면 갑작스러운 flush가 발생할 수 있음innodb_max_dirty_pages_pct_lwm을 적절히 설정해 디스크 쓰기 작업을 분산innodb_io_capacity는 디스크의 IOPS 성능에 맞게 조정innodb_adaptive_flushing은 더티 페이지 증가율에 따라 플러시 빈도를 자동으로 조정innodb_flush_neighbors는 HDD 환경에서는 활성화, SSD 환경에서는 비활성 권장
4.2.7.4.2 LRU 리스트 플러시
- 자주 사용되지 않는 페이지를 제거하기 위해 LRU 리스트 뒤쪽에서 클린 페이지와 더티 페이지를 구분
- 클린 페이지는 바로 제거, 더티 페이지는 먼저 플러시 후 제거
- 플러시 대상 페이지 수는
innodb_lru_scan_depth에 따라 결정 - 실제 스캔 수는
innodb_buffer_pool_instances * innodb_lru_scan_depth로 계산
4.2.7.5 버퍼 풀 상태 백업과 성능 영향
1. 버퍼 풀은 디스크 대신 자주 접근하는 데이터를 메모리에 보관하는 공간
- InnoDB의 버퍼 풀은 자주 사용되는 데이터와 인덱스를 메모리에 유지
- 디스크 대신 메모리에서 직접 읽을 수 있어 쿼리 속도가 비약적으로 향상됨
2. 서버 재시작 시 버퍼 풀은 초기화됨
- MySQL 서버가 재시작되면 버퍼 풀의 캐시 데이터는 모두 삭제
- 서버가 처음 시작되는 순간 모든 쿼리가 디스크에 직접 접근해야 처리
- 이로 인해 서비스 초기 성능이 평소 대비 1/10 이하로 하락 가능
3. 캐시 백업은 어떤 정보를 저장하는가
- 실제 데이터가 아닌, 자주 사용된 페이지 번호 등의 메타 정보만 저장
- MySQL 재시작 후 해당 페이지를 우선적으로 버퍼 풀에 로딩
- 자주 사용되는 인덱스와 데이터가 빠르게 준비됨
4. 백업/복구 시나리오 비교
| 상황 | 버퍼 풀 백업 ❌ | 버퍼 풀 백업 ✅ |
|---|---|---|
| 서버 재시작 후 성능 | 느림. 디스크 I/O 폭주 발생 가능 | 빠름. 쿼리가 즉시 메모리에서 처리 가능 |
| 워밍업 시간 | 수 분~수십 분 | 수 초~수십 초 |
| 대규모 트래픽 대응 시 초기 지연 | 타임아웃 발생 가능성 | 평소 성능과 유사한 응답 시간 유지 |
5. 실무 활용 효과
- 쿼리 캐시 히트율이 높은 서비스에서 특히 성능 개선 효과가 큼
- 뉴스, 쇼핑몰, 금융 등 실시간 반응이 중요한 서비스에 매우 유효
- 서버 재기동 후 트래픽 폭주 상황에서 안정성 확보
6. 결론
- 버퍼 풀 상태 백업은 MySQL 서버의 워밍업을 단축하고 초기 성능 저하를 방지
- 메모리 기반 캐시를 사전에 준비해 서비스의 응답성과 안정성을 보장
4.2.7.6 버퍼 풀의 적재 내용 확인
개요
- MySQL 5.6까지는
innodb_buffer_page테이블로 InnoDB 버퍼 풀의 적재 상태를 확인할 수 있었지만, 버퍼 풀이 크면 성능 저하로 실무에서는 사용 어려움 - MySQL 8.0부터
information_schema.innodb_cached_indexes테이블 도입 - 테이블 및 인덱스의 페이지가 얼마나 버퍼 풀에 적재되었는지 효율적으로 확인 가능
1. 인덱스별 적재 페이지 수 확인
SELECT
it.name AS table_name,
ii.name AS index_name,
ici.n_cached_pages
FROM information_schema.innodb_tables it
JOIN information_schema.innodb_indexes ii ON ii.table_id = it.table_id
JOIN information_schema.innodb_cached_indexes ici ON ici.index_id = ii.index_id
WHERE it.name = CONCAT('employees', '/', 'employees');2. 전체 페이지 대비 캐시 비율 확인
SELECT
(SELECT SUM(ici.n_cached_pages)
FROM information_schema.innodb_tables it
JOIN information_schema.innodb_indexes ii ON ii.table_id = it.table_id
JOIN information_schema.innodb_cached_indexes ici ON ici.index_id = ii.index_id
WHERE it.name = CONCAT(t.table_schema, '/', t.table_name)) AS total_cached_pages,
((t.data_length + t.index_length - t.data_free) / @@innodb_page_size) AS total_pages
FROM information_schema.tables t
WHERE t.table_schema = 'employees'
AND t.table_name = 'employees';| 항목 | 내용 |
|---|---|
| 주요 뷰 | information_schema.innodb_cached_indexes |
| 확인 가능한 정보 | 인덱스별 캐시된 페이지 수 |
| 주요 활용 목적 | 쿼리 성능 분석, 버퍼 풀 캐시 적중률 추정 |
| 장점 | 가볍고 빠르게 버퍼 풀 적재 현황 파악 가능 |
| 한계 | 테이블 전체 페이지 목록은 제공하지 않음 |
4.2.8 Double Write Buffer
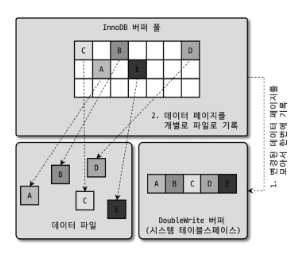
개요
- InnoDB는 디스크에 더티 페이지를 플러시할 때, 일부만 기록되는 문제(Partial Write) 를 방지하기 위해 Double Write Buffer 사용
- 이러한 문제는 하드웨어 이상, 전원 장애 등으로 인해 발생 가능
개념
- 디스크에 실제로 페이지를 쓰기 전에, 변경된 페이지(A~E 등)를 먼저 시스템 테이블스페이스의 DoubleWrite 버퍼 영역에 일괄 기록
- 이후 실제 데이터 파일에 각각의 페이지를 랜덤하게 기록
동작 방식
- A~E 페이지를 DoubleWrite 버퍼에 순차적으로 기록
- DoubleWrite 버퍼에 기록 완료 후, 각 페이지를 실제 데이터 파일에 랜덤 위치에 기록
- MySQL 재시작 시 DoubleWrite 버퍼와 데이터 파일의 내용을 비교해 손상된 페이지를 복구
장점
- 데이터 무결성 보장: 페이지가 부분적으로만 기록되는 상황 방지
- 시스템 충돌 시에도 복구 가능성 향상
단점
- SSD에서는 순차 IO와 랜덤 IO 차이가 거의 없음 → 성능 이점 적음
- HDD처럼 플래터 기반 스토리지에서 효과 큼
관련 설정
| 변수 | 설명 |
|---|---|
innodb_doublewrite |
DoubleWrite 버퍼 사용 여부 (기본 ON) |
innodb_flush_log_at_trx_commit |
Redo 로그 커밋 동기화 관련 설정 |
innodb_flush_log_at_trx_commit = 1 |
트랜잭션마다 리두 로그를 디스크에 동기화, DoubleWrite와 함께 사용 권장 |
주의 사항
innodb_flush_log_at_trx_commit이 1이 아닐 경우, DoubleWrite만으로는 복구 보장 불가- 고가용성 시스템에서는 리두 로그 + DoubleWrite + 바이너리 로그 등의 다중 복제 방식으로 운영 권장
4.2.9 Undo 로그
개요
- InnoDB 스토리지 엔진은 트랜잭션의 원자성과 격리 수준을 보장하기 위해 Undo 로그를 사용
- Undo 로그는 DML (
INSERT,UPDATE,DELETE) 쿼리 수행 시 변경 전 데이터를 별도로 백업하는 공간 - 이를 통해 롤백 시 이전 상태로 복원하거나, 다중 트랜잭션의 일관된 뷰를 제공 (MVCC)
Undo 로그의 주요 기능
| 기능 | 설명 |
|---|---|
| 트랜잭션 롤백 | 트랜잭션 도중 오류 발생 시 변경 전 상태로 복원 |
| 격리 수준 보장 | 다른 트랜잭션이 변경 중인 데이터를 조회할 때, 백업된 데이터를 기반으로 읽기 |
Undo 로그의 작동 방식 요약
- 트랜잭션이 시작되면 변경 전 데이터를 Undo 로그에 기록
- 커밋되면 Undo 로그는 이후 Purge 스레드에 의해 제거 대상이 됨
- 롤백되면 Undo 로그를 이용해 데이터 복구
- MVCC에서는 Undo 로그를 통해 트랜잭션 간 Read View 제공
4.2.9.1 Undo 로그 레코드 모니터링
🔹 Undo 로그 예시
UPDATE member SET name='홍길동' WHERE member_id=1;4.2.9.1 Undo 로그 레코드 모니터링
Undo 로그의 내부 작동 방식
- 트랜잭션이 시작되면 변경 전 데이터가 Undo 영역에 백업
- 트랜잭션이 커밋되지 않으면 Undo 로그는 계속 유지
- 롤백 시에는 Undo 영역의 데이터를 이용해 복구
Undo 로그의 주요 사용 목적
- 트랜잭션 롤백 처리
- 트랜잭션 중간에 에러가 발생하면 Undo 로그를 통해 이전 상태로 되돌림
- 격리 수준 보장 (MVCC)
- 동시에 다른 트랜잭션이 데이터를 읽을 때 변경 전 상태를 보여주기 위해 Undo 로그 사용
Undo 로그의 공간 증가 원인
- MySQL 5.5 이전 버전에서는 Undo 로그가 자동으로 줄어들지 않음
- 예시: 한 번 생성된 100GB 테이블을 DELETE하면 Undo 로그로 100GB가 추가적으로 기록됨
- 테이블 크기가 크면 Undo 로그의 사이즈도 기하급수적으로 증가
Undo 로그가 많이 사용되는 상황
- 대용량 트랜잭션 수행 시 (수백만 건 DELETE/UPDATE)
- 장시간 오픈된 트랜잭션이 커밋되지 않고 유지되는 경우
- 서비스에서 트랜잭션이 BEGIN 후 COMMIT 없이 방치된 경우
트랜잭션과 Undo 로그의 관계 예시
BEGIN; – 트랜잭션 A 시작
UPDATE …; – 변경, Undo 로그 기록
COMMIT; – 트랜잭션 A 종료
BEGIN; – 트랜잭션 B 시작
UPDATE …; – 변경, Undo 로그 기록
BEGIN; – 트랜잭션 C 시작
DELETE …; – 변경, Undo 로그 기록- 트랜잭션 A는 종료되었으므로 Undo 로그가 제거 가능
- 트랜잭션 B와 C는 아직 미완료이므로 Undo 로그는 계속 유지됨
- 오래 실행되는 트랜잭션이 많을수록 Undo 로그가 적체됨
실무에서 발생하는 문제
- 애플리케이션 오류나 개발자의 실수로 BEGIN만 실행되고 COMMIT 또는 ROLLBACK이 없는 경우
- Undo 로그가 계속 증가하면서 디스크 공간을 소모
- 리두 로그(Redo Log)와 달리 자동 회수까지 오래 걸릴 수 있음
모니터링 명령어
모든 MySQL 버전에서 공통
SHOW ENGINE INNODB STATUS \G- History list length 항목을 통해 Undo 로그 적체 상태 확인
MySQL 8.0 이상
SELECT count
FROM information_schema.innodb_metrics
WHERE SUBSYSTEM = 'transaction'
AND NAME = 'trx_rseg_history_len';- Undo 로그 레코드 수를 명확하게 확인 가능
4.2.9.2 언두 테이블스페이스 관리
개요
- Undo 로그는
Undo Tablespace라는 전용 저장 공간에 보관된다. - MySQL 5.6 이전: Undo 로그는
시스템 테이블스페이스 (ibdata1)에 저장 - MySQL 5.6부터:
innodb_undo_tablespaces시스템 변수로 별도 Undo Tablespace 사용 가능 - MySQL 8.0부터:
innodb_undo_tablespaces설정은 deprecated 처리 → 항상 외부 파일에 기록됨
Undo Tablespace 구조
- 하나의 Undo Tablespace는 최대 128개의
Rollback 세그먼트를 가질 수 있음 - 하나의 Rollback 세그먼트는 하나 이상의
Undo 슬롯 (Undo Slot)을 가짐 - Undo 슬롯 개수는 InnoDB 페이지 크기 및 트랜잭션 수에 따라 결정됨
최대 동시 트랜잭션 수 계산식
최대 동시 트랜잭션 수 = (InnoDB 페이지 크기 / 16) * (Rollback 세그먼트 수) * (Undo 테이블스페이스 수)
- 예시:
- 페이지 크기: 16KB
- Rollback 세그먼트 수: 128
- Undo Tablespace 수: 2
- → 최대 동시 트랜잭션 수 = 131072
Undo Tablespace 관리 명령어 (MySQL 8.0 이후)
-- Undo Tablespace 목록 확인
SELECT TABLESPACE_NAME, FILE_NAME
FROM INFORMATION_SCHEMA.FILES
WHERE FILE_TYPE LIKE 'UNDO LOG';
-- Undo Tablespace 추가
CREATE UNDO TABLESPACE extra_undo_003
ADD DATAFILE '/data/undo_dir/undo_003';
-- Undo Tablespace 비활성화
ALTER UNDO TABLESPACE extra_undo_003 SET INACTIVE;
-- 비활성화된 Undo Tablespace 삭제
DROP UNDO TABLESPACE extra_undo_003;Undo Tablespace 공간 정리 (Truncate)
- Undo 로그가 오래 남아있으면 디스크 공간이 낭비되므로 Truncate를 통해 공간 회수 필요
- MySQL 8.0 이상에서는 자동 및 수동 Truncate 지원
자동 Truncate
innodb_purge_rseg_truncate_frequency설정에 따라 Purge 스레드가 주기적으로 자동 정리
수동 Truncate
- 명시적으로 공간을 줄이고 싶을 때 사용
- 최소 3개의 Undo Tablespace가 있어야 가능
- 사용 방법:
ALTER UNDO TABLESPACE undo_003 SET INACTIVE;
→ 공간 회수 후ALTER UNDO TABLESPACE undo_003 SET ACTIVE;
요약
| 항목 | 설명 |
|---|---|
| 자동 Truncate | 주기적으로 Purge 스레드가 자동으로 실행 |
| 수동 Truncate | INACTIVE → ACTIVE 전환 방식으로 수동 회수 |
| 조건 | 최소 3개의 Undo Tablespace 필요, 비활성화 상태에서만 회수 가능 |
| 목적 | 디스크 공간 효율 확보 |
4.2.10 체인지 버퍼
- 인덱스 변경을 메모리에서 버퍼링하여 디스크 작업 부담 경감
- Merge thread가 버퍼 머지 수행
사용
- 기본값: 버퍼 풀의 25% 사용
- 필요시 최대 50%까지 사용 가능
- 변수: innodb_change_buffer_max_size로 조정
모니터링
- performance_schema.memory_summary_global_by_event_name로 확인
- SHOW ENGINE INNODB STATUS에서 관련 정보 확인
4.2.11 리두 로그 및 로그 버퍼
- 리두 로그는 트랜잭션 커밋 전 변경 내용을 디스크에 기록하기 위한 로그
- 로그 버퍼는 메모리에서 리두 로그 항목을 임시 저장하는 영역
리두 로그의 구조
- 고정 크기의 순환 로그 파일로 구성 판단
- 각 로그 항목에 LSN(Log Sequence Number) 부여
- 체크포인트 시점에 디스크로 플러시되어 로그 공간 재사용
로그 버퍼의 역할
- 변경 내용을 임시 저장 후, 주기적으로 디스크에 기록
- 트랜잭션 커밋 시 로그 버퍼의 내용이 반드시 디스크에 기록되어야 함
- innodb_log_buffer_size 변수로 크기 조정
동작 과정
- 트랜잭션 변경 내용 발생 → 로그 버퍼에 기록
- 일정 시점 또는 트랜잭션 커밋 시 → 로그 버퍼 내용 디스크로 플러시
- 장애 발생 시 → 리두 로그를 사용해 데이터 복구
효과 및 주의사항
- 리두 로그를 통해 장애 복구와 데이터 내구성을 보장
- 로그 버퍼 크기가 작으면 잦은 플러시로 I/O 부하 증가
- 로그 버퍼 크기 조정이 전체 시스템 성능에 큰 영향을 미침
4.2.11.2리두 로그 활성화/비활성화
InnoDB에서 Redo 로그(리두 로그)는 기본적으로 항상 사용되는 필수 요소입니다. 완전히 끄는(비활성화하는) 설정은 거의 없고, 대신 “로그를 얼마나 즉시 디스크에 기록할지(동기화 정책)”를 제어하는 방식으로 “강하게(on)/약하게(off)” 비슷한 효과를 냅니다.
핵심 시스템 변수: innodb_flush_log_at_trx_commit
- 값=1
- 트랜잭션이 COMMIT할 때마다 로그 버퍼 → 디스크로 즉시 flush
- 가장 안전(0초 이하 데이터 손실 없음)
- 디스크 I/O가 많아져 성능 부담
- “Redo 로그를 완전히 활성화”한 상태로 볼 수 있음
- 값=0
- COMMIT 시점에 디스크로 flush하지 않음
- OS가 임의 시점에 쓰므로, 장애 발생 시 마지막 커밋 ~ 장애 사이 데이터 유실 위험
- “Redo 로그를 매우 약하게(거의 비활성화 수준)” 쓰는 상태
- 값=2
- COMMIT 시점에 로그 버퍼를 OS 캐시까지는 옮기지만, 디스크 동기화(fsync)는 일정 주기로만 함
- 데이터 유실 가능성은 0보다 적지만 1보다 큼
- 적당히 성능과 안전성 타협
즉, InnoDB에서 ‘Redo 로그 활성화/비활성화’를 직접 명령어로 ON/OFF 하진 않고,innodb_flush_log_at_trx_commit 값을 통해 실제로 얼마나 확실히 로그를 디스크에 기록할지를 결정함
비활성화한다고 해서 Redo 로그 자체가 아예 없어지는 것은 아님
- 완전히 로그를 없애면 장애 발생 시 복구가 불가능해지므로 실무에서 거의 사용 불가
- 대부분은 “로그 기록을 지연”시켜 성능을 높이려는 용도로 0이나 2를 쓰기도 함
4.2.12 어댑티브 해시 인덱스
- 기본 개념
- 일반 인덱스는 사용자가 생성한 B-Tree 인덱스임
- 어댑티브 해시 인덱스는 InnoDB가 자주 검색되는 데이터에 대해 자동으로 생성하는 해시 인덱스임
- 이 인덱스는 버퍼 풀에 로딩된 데이터 페이지에 한해 적용되며, 데이터 페이지가 메모리에서 사라지면 해당 인덱스 정보도 사라짐
- 작동 원리
- InnoDB는 데이터 페이지를 메모리(버퍼 풀)에 로딩할 때, 그 페이지의 인덱스 키와 메모리 주소를 기록함
- 어댑티브 해시 인덱스는 이 정보를 이용해, B-Tree의 루트부터 리프까지 검색하는 대신 해시 함수를 사용해 바로 데이터 페이지를 찾아냄
- 즉, 해시 인덱스를 통해 데이터 페이지의 메모리 주소를 즉시 확인하여 쿼리 처리 속도를 높임
- 장점
- B-Tree 검색 과정(루트부터 리프까지)을 생략하여 CPU 부하를 줄임
- 동등 조건 검색(예: =, IN 연산자)에서 쿼리 처리량을 크게 증가시킴
- 결과적으로 서버의 응답속도가 빨라지고, CPU 사용률이 낮아짐
- 단점 및 주의 사항
- 버퍼 풀에 데이터가 없으면 어댑티브 해시 인덱스도 작동하지 않음
- 디스크 I/O가 많은 환경이나, 범위 검색(LIKE, 조인 등)에는 효과가 미미함
- 추가 메모리를 사용하므로, 메모리 자원에 부담이 될 수 있음
- 테이블 삭제나 스키마 변경 시, 해시 인덱스의 정보도 정리해야 하므로 작업 시간이 길어질 수 있음
- 내부 경합 문제 개선
- 초기 버전에서는 하나의 메모리 객체로 관리되어 잠금 경합이 심했음
- MySQL 8.0부터는 파티션 기능을 도입하여, 어댑티브 해시 인덱스를 여러 파티션으로 분할함
- 파티션 개수는
innodb_adaptive_hash_index_parts변수로 조정하며, 기본값은 8 - 이를 통해 내부 잠금 경합을 줄여 성능 향상에 도움을 줌
- 실제 성능 효과
- 어댑티브 해시 인덱스 활성화 전에는 초당 20,000건 정도의 쿼리 처리 시 CPU 사용률이 100%에 달함
- 활성화 후에는 처리량이 2배 가까이 늘어나면서도 CPU 사용률은 오히려 낮아짐
- 이는 B-Tree의 검색 횟수를 줄이고, 내부 잠금(세마포어) 횟수를 크게 감소시킴
4.4 MySQL 로그 파일
4.4.1 에러 로그 파일
에러 로그 파일은 MySQL 설정 파일(my.cnf)에서 log_error라는 이름의 파라미터로 정의된 경로로 생성됨
따로 정의하지 않으면 데이터 디렉터리에 .err라는 확장자가 붙은 파일로 생성
제너럴 쿼리 로그 파일
4.4.2 제너럴 쿼리 로그 파일 (General log)
제너럴 로그란?
- MySQL 서버에서 실행되는 모든 쿼리를 기록하는 로그
- 시스템에서 어떤 쿼리가 실행되었는지 전체적으로 추적하고자 할 때 유용
- 슬로우 쿼리 로그와는 다르게, 실행되기 전의 쿼리 요청 내용까지 기록
- 따라서 실행 중 에러가 나더라도, 쿼리 자체는 로그에 남음
로그 예시
2020-07-19T15:27:34.549010+09:00 14 Connect root@localhost on using Socket
2020-07-19T15:27:34.549179+09:00 14 Query select @@version_comment limit 1
2020-07-19T15:27:43.878749+09:00 14 Query show databases
...- 시간, 커넥션 ID, 실행된 명령 유형 (Query, Connect 등), 실행된 쿼리 내용이 기록됨
로그 파일 경로 설정
- 로그 파일 경로는
general_log_file이라는 시스템 변수에 설정
SHOW GLOBAL VARIABLES LIKE 'general_log_file';예시 결과:
+------------------+---------------------------------------------+
| Variable_name | Value |
+------------------+---------------------------------------------+
| general_log_file | /usr/local/mysql/data/localhost_matt.log |
+------------------+---------------------------------------------+- 로그가 파일로 저장되며, 이 경로에서 로그를 직접 확인 가능
파일 또는 테이블로 저장 여부
- 로그는 파일 또는 테이블 중 선택하여 저장 가능
- 저장 방식은
log_output이라는 파라미터로 결정됨:'FILE','TABLE','NONE'가능'TABLE'로 설정하면mysql.general_log테이블에 저장됨
SHOW VARIABLES LIKE 'log_output';4.4.3 슬로우 쿼리란?
슬로우 쿼리는 MySQL에서 실행 시간이 오래 걸리는 쿼리를 의미하며, 서버 성능 저하의 원인이 되는 쿼리를 분석하는 데 사용
슬로우 쿼리 로그 설정
slow_query_log: 슬로우 쿼리 로그 활성화 여부 (ON/OFF)long_query_time: 슬로우 쿼리로 간주할 최소 실행 시간 (초)log_output: 로그 저장 위치 설정 (FILE,TABLE,NONE)
SET GLOBAL slow_query_log = 'ON';
SET GLOBAL long_query_time = 1;로그 저장 형식
# Time: 2020-07-19T15:44:22.178484+09:00
# User@Host: root[root] @ localhost []
# Query_time: 1.180245 Lock_time: 0.002658 Rows_sent: 1 Rows_examined: 2844047
SET timestamp=1595144106;
SELECT emp_no, max(salary) FROM salaries;Query_time: 쿼리 실행에 소요된 전체 시간Lock_time: 테이블 잠금 대기 시간Rows_examined: 스캔한 행 수Rows_sent: 결과로 반환된 행 수
분석 도구: pt-query-digest
Percona Toolkit의 pt-query-digest를 이용해 슬로우 쿼리 로그를 분석할 수 있음
pt-query-digest --type=slowlog mysql-slow.log > parsed_slow.log분석 결과 예시
- 슬로우 쿼리 통계 요약
- 쿼리별 실행 시간 및 호출 수 정렬
- 쿼리별 상세 실행 통계 및 분포 정보
주의 사항
- 슬로우 쿼리 로그는 데이터가 많아질 수 있으므로 필터링 및 주기적 분석이 필요함
- InnoDB 사용 시
Lock_time수치가 낮게 나올 수 있으므로 주의
'SQL' 카테고리의 다른 글
| REAL MySQL 5장 트랜잭션 (0) | 2025.04.14 |
|---|