
Spring Batch
Spring Batch가 제공하는 영역
1. 핵심 실행 컴포넌트
Job과 Step
- Job: 배치 작업의 최상위 개념으로, 하나 이상의 Step으로 구성
- Step: 실제 배치 작업을 수행하는 단위로, Job의 구성 요소
JobLauncher
- Job을 실행하고 실행에 필요한 파라미터를 전달하는 역할
- 배치 작업 실행의 시작점
- 동기/비동기 실행 방식 지원
JobRepository
- 배치 처리의 모든 메타데이터를 저장하고 관리하는 핵심 저장소
- Job과 Step의 실행 정보(시작/종료 시간, 상태, 결과 등)를 기록
- 배치 작업의 모니터링이나 문제 발생 시 재실행에 활용
ExecutionContext
- Job과 Step 실행 중의 상태 정보를 key-value 형태로 담는 객체
- Job과 Step 간의 데이터 공유나 Job 재시작 시 상태 복원에 사용
2. 데이터 처리 컴포넌트 구현체
Spring Batch는 데이터를 '읽기-처리-쓰기' 방식으로 처리하며 이를 위한 다양한 구현체를 제공
ItemReader 구현체
다양한 데이터 소스로부터 데이터를 읽어올 수 있다:
- JdbcCursorItemReader: JDBC를 통한 데이터베이스 읽기
- JpaPagingItemReader: JPA를 사용한 페이징 방식 읽기
- MongoCursorItemReader: MongoDB 데이터 읽기
- FlatFileItemReader: CSV, TXT 등 파일 읽기
- JsonItemReader: JSON 파일 읽기
ItemWriter 구현체
처리된 데이터를 다양한 저장소에 저장할 수 있다:
- JdbcBatchItemWriter: JDBC를 통한 배치 데이터베이스 쓰기
- JpaItemWriter: JPA를 사용한 데이터베이스 쓰기
- MongoItemWriter: MongoDB 데이터 쓰기
- FlatFileItemWriter: 파일 쓰기
- JsonFileItemWriter: JSON 파일 쓰기
ItemProcessor
- 읽은 데이터를 처리하고 변환하는 중간 처리 단계
- 필터링, 변환, 검증 등의 로직 구현 가능
3. 배치 작업의 생명주기
- Job 시작: JobLauncher가 Job을 실행
- Step 실행: Job 내의 각 Step이 순차적으로 실행
- 데이터 처리: ItemReader → ItemProcessor → ItemWriter 순서로 처리
- 메타데이터 저장: JobRepository에 실행 정보 저장
- 완료/실패: 작업 완료 또는 실패 시 적절한 처리
개발자가 제어하는 영역
Spring Batch가 제공하는 컴포넌트들을 활용하여 개발자가 직접 작성하고 제어해야 하는 부분
1. Job/Step 구성
@Configuration을 사용한 배치 작업 정의
- Job과 Step의 실행 흐름을 정의
- 각 Step의 실행 순서와 조건을 설정
- Spring 컨테이너에 등록해 배치 잡의 동작을 구성
- Spring의 DI(의존성 주입)를 활용해 컴포넌트들을 조합
기본 배치 잡 구성 예제
@Bean
public Job dataTerminationJob(Step terminateStep) {
return new JobBuilder("dataTerminationJob", jobRepository)
.start(terminateStep)
.build();
}
@Bean
public Step terminateStep(ItemReader<String> itemReader, ItemWriter<String> itemWriter) {
return new StepBuilder("terminateStep", jobRepository)
.<String, String>chunk(10, transactionManager)
.reader(itemReader)
.writer(itemWriter)
.build();
}
@Bean
public ItemReader<String> itemReader() {
// return ItemReader 구현체
}
@Bean
public ItemWriter<String> itemWriter() {
// return ItemWriter 구현체
}2. 데이터 처리 컴포넌트 활용
세부 로직 구현
- Spring Batch는 ItemReader, ItemWriter 구현체를 제공하지만 세부 로직은 개발자가 직접 지정
- 예: FlatFileItemReader로 CSV 파일 읽을 때 컬럼 매핑 방식은 개발자가 지정
- SQL 쿼리 조건, 파일 포맷 등 구체적인 처리 로직 구현 필요
3. 단순 작업 처리
직접 구현이 필요한 작업들
- 파일 복사, 디렉토리 정리, 알림 발송 등 단순 작업
- Spring Batch가 제공하는 포인트를 활용하여 구현
- 단순해 보여도 시스템 안정성에 중요한 역할
4. 커스텀 데이터 처리 컴포넌트
ItemReader/ItemWriter 직접 구현
- Spring Batch가 제공하지 않는 데이터 소스 처리 시 필요
- 예: 특정 데이터베이스, 새로운 포맷 등
- MongoDB Cursor 기반 ItemReader, Redis ItemReader/ItemWriter 등
ItemProcessor 구현
- 읽은 데이터를 가공하고 필터링하는 역할
- 비즈니스 로직의 핵심을 담당
- 개발자가 직접 구현해야 하는 핵심 컴포넌트
5. 개발자의 책임
- 배치 작업 설계: Job과 Step의 구조 설계
- 비즈니스 로직 구현: ItemProcessor를 통한 데이터 처리 로직
- 데이터 소스 연결: ItemReader/ItemWriter를 통한 데이터 입출력
- 에러 처리: 예외 상황에 대한 적절한 처리
- 성능 최적화: 청크 크기, 병렬 처리 등 최적화 설정
데이터 처리 컴포넌트 활용
핵심 컴포넌트
- ItemReader: 데이터 소스에서 데이터를 읽어오는 컴포넌트
- ItemWriter: 처리된 데이터를 저장소에 쓰는 컴포넌트
- ItemProcessor: 읽은 데이터를 가공하고 필터링하는 컴포넌트
개발자가 직접 구현해야 하는 부분
- 세부 로직: 파일 포맷, SQL 쿼리 조건, 컬럼 매핑 방식 등
- 비즈니스 로직: ItemProcessor를 통한 데이터 가공 및 필터링
- 커스텀 컴포넌트: Spring Batch가 제공하지 않는 데이터 소스 처리
단순 작업 처리
- 파일 복사, 디렉토리 정리, 알림 발송 등
- Spring Batch가 제공하는 포인트를 활용하여 직접 구현
실제 배치 시스템 구축
두 가지 접근 방식
1. 원시적 방식 (Spring)
- Spring Boot 없이 순수 Spring + Spring Batch 사용
- 모든 설정을 수동으로 구성
- 필요한 Bean들을 수동 등록
- CommandLineJobRunner로 명령줄에서 배치 실행
- @Import와 BaseConfig 분리 필요
- Spring Boot 편리함을 느끼기 위한 기초 학습용
2. Spring Boot 방식
- Spring Boot 자동 설정 활용
- 복잡한 설정은 프레임워크가 자동 처리
- 개발자는 핵심 비즈니스 로직에만 집중
- JobLauncherApplicationRunner가 자동으로 배치 실행
- @Import와 BaseConfig 불필요, @Configuration 하나로 해결
메인 애플리케이션 클래스
@SpringBootApplication
public class KillBatchSystemApplication {
public static void main(String[] args) {
System.exit(SpringApplication.exit(SpringApplication.run(KillBatchSystemApplication.class, args)));
}
}System.exit() 사용 이유
- 배치 작업 성공/실패 상태를 exit code로 외부 시스템에 전달
- 실무에서 배치 모니터링과 제어에 필수
- 정상 완료: 0, 실패: 0이 아닌 값 반환
- 외부 스케줄러나 모니터링 시스템에서 배치 실행 결과 판단 가능
핵심 차이점
- 원시적 방식: 모든 설정을 수동으로 구성, CommandLineJobRunner 사용
- Spring Boot 방식: 자동 설정 활용, JobLauncherApplicationRunner가 자동으로 배치 실행
2단계: HelloDeath Batch - 첫 번째 배치 시스템 구축
배치 작업 시나리오
- 시스템 접속 (enterWorldStep)
- 관리자 확인 (meetNPCStep)
- 프로세스 처리 (defeatProcessStep)
- 작업 완료 (completeQuestStep)
Spring 구현
BatchConfig - 기본 설정
@Configuration
public class BatchConfig extends DefaultBatchConfiguration {
@Bean
public DataSource dataSource() {
return new EmbeddedDatabaseBuilder()
.setType(EmbeddedDatabaseType.H2)
.addScript("org/springframework/batch/core/schema-h2.sql")
.build();
}
@Bean
public PlatformTransactionManager transactionManager() {
return new DataSourceTransactionManager(dataSource());
}
}SystemTerminationConfig - 비즈니스 로직
@Import(BatchConfig.class)
public class SystemTerminationConfig {
private final JobRepository jobRepository;
private final PlatformTransactionManager transactionManager;
public SystemTerminationConfig(JobRepository jobRepository, PlatformTransactionManager transactionManager) {
this.jobRepository = jobRepository;
this.transactionManager = transactionManager;
}
@Bean
public Job systemTerminationSimulationJob() {
return new JobBuilder("systemTerminationSimulationJob", jobRepository)
.start(enterWorldStep())
.next(meetNPCStep())
.next(defeatProcessStep())
.next(completeQuestStep())
.build();
}
@Bean
public Step enterWorldStep() {
return new StepBuilder("enterWorldStep", jobRepository)
.tasklet((contribution, chunkContext) -> {
System.out.println("배치 시스템에 접속했습니다!");
return RepeatStatus.FINISHED;
}, transactionManager)
.build();
}
}Spring Boot 방식 구현
SystemTerminationConfig - 단일 설정으로 해결
@Configuration
public class SystemTerminationConfig {
private final JobRepository jobRepository;
private final PlatformTransactionManager transactionManager;
public SystemTerminationConfig(JobRepository jobRepository, PlatformTransactionManager transactionManager) {
this.jobRepository = jobRepository;
this.transactionManager = transactionManager;
}
@Bean
public Job systemTerminationSimulationJob() {
return new JobBuilder("systemTerminationSimulationJob", jobRepository)
.start(enterWorldStep())
.next(meetNPCStep())
.next(defeatProcessStep())
.next(completeQuestStep())
.build();
}
}핵심 차이점
- 원시적 방식: @Import(BatchConfig.class) 필요, BaseConfig 분리
- Spring Boot 방식: @Import 불필요, @Configuration 하나로 모든 설정 해결
- 자동 주입: Spring Boot가 JobRepository, PlatformTransactionManager 자동 구성
배치 처리의 두 가지 방식: Chunk와 Tasklet
Step의 두 가지 처리 모델
- 청크 지향 처리 (Chunk-Oriented Processing): 데이터 기반 처리 (읽기-처리-쓰기)
- 태스크릿 지향 처리 (Tasklet-Oriented Processing): 단순 작업 처리
Tasklet 지향 처리
사용 시나리오
- 매일 새벽 불필요한 로그 파일 삭제
- 특정 디렉토리에서 오래된 파일을 아카이브
- 사용자에게 단순한 알림 메시지 또는 이메일 발송
- 외부 API 호출 후 결과를 단순히 저장하거나 로깅
Tasklet 인터페이스
@FunctionalInterface
public interface Tasklet {
@Nullable
RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception;
}Tasklet 구현 예시
@Slf4j
public class ZombieProcessCleanupTasklet implements Tasklet {
private final int processesToKill = 10;
private int killedProcesses = 0;
@Override
public RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {
killedProcesses++;
log.info("프로세스 강제 종료... ({}/{})", killedProcesses, processesToKill);
if (killedProcesses >= processesToKill) {
log.info("시스템 안정화 완료. 모든 프로세스 제거.");
return RepeatStatus.FINISHED;
}
return RepeatStatus.CONTINUABLE;
}
}RepeatStatus
- FINISHED: Step 완료, 다음 단계로 진행
- CONTINUABLE: 추가 실행 필요, execute() 메서드 반복 호출
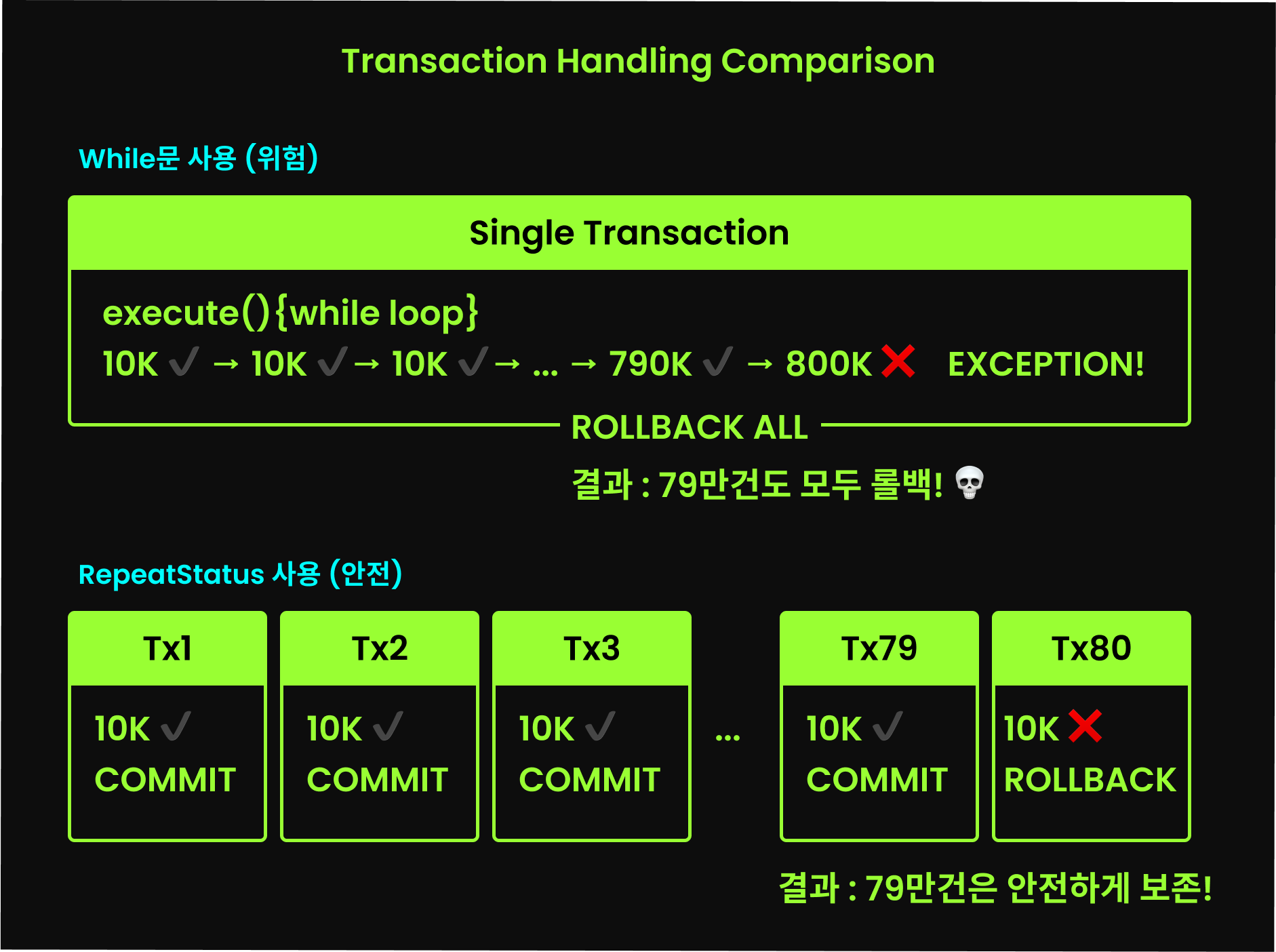
RepeatStatus 사용 이유
- 짧은 트랜잭션을 활용한 안전한 배치 처리
- 반복문 대신 Spring Batch가 트랜잭션 관리
- 예외 발생 시에도 이미 처리된 데이터는 안전하게 보존
Tasklet을 Step으로 등록
@Configuration
public class ZombieBatchConfig {
private final JobRepository jobRepository;
private final PlatformTransactionManager transactionManager;
@Bean
public Tasklet zombieProcessCleanupTasklet() {
return new ZombieProcessCleanupTasklet();
}
@Bean
public Step zombieCleanupStep() {
return new StepBuilder("zombieCleanupStep", jobRepository)
.tasklet(zombieProcessCleanupTasklet(), transactionManager)
.build();
}
@Bean
public Job zombieCleanupJob() {
return new JobBuilder("zombieCleanupJob", jobRepository)
.start(zombieCleanupStep())
.build();
}
}ResourcelessTransactionManager
- DB 작업이 없는 Tasklet에서 사용
- 불필요한 DB 트랜잭션 처리 생략
@Bean public Step zombieCleanupStep() { return new StepBuilder("zombieCleanupStep", jobRepository) .tasklet(zombieProcessCleanupTasklet(), new ResourcelessTransactionManager()) .build(); }
Tasklet 사용 시나리오 예시
1. 오래된 파일 삭제
@Slf4j
public class DeleteOldFilesTasklet implements Tasklet {
private final String path;
private final int daysOld;
@Override
public RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) {
File dir = new File(path);
long cutoffTime = System.currentTimeMillis() - (daysOld * 24 * 60 * 60 * 1000L);
File[] files = dir.listFiles();
if (files != null) {
for (File file : files) {
if (file.lastModified() < cutoffTime) {
if (file.delete()) {
log.info("파일 삭제: {}", file.getName());
}
}
}
}
return RepeatStatus.FINISHED;
}
}2. 람다식으로 간단한 Tasklet 구현
@Bean
public Step deleteOldRecordsStep() {
return new StepBuilder("deleteOldRecordsStep", jobRepository)
.tasklet((contribution, chunkContext) -> {
int deleted = jdbcTemplate.update("DELETE FROM logs WHERE created < NOW() - INTERVAL 7 DAY");
log.info("{}개의 오래된 레코드가 삭제되었습니다.", deleted);
return RepeatStatus.FINISHED;
}, transactionManager)
.build();
}Tasklet 지향 처리 특징
- 단순 작업에 적합: 알림 발송, 파일 복사, 오래된 데이터 삭제 등
- Tasklet 인터페이스 구현: 필요한 로직을 작성하고 StepBuilder.tasklet()에 전달
- RepeatStatus로 실행 제어: execute() 메서드 반환값으로 반복 여부 결정
- 트랜잭션 지원: Spring Batch가 execute() 메서드 실행 전후로 트랜잭션 관리
Chunk 지향 처리
Chunk란?
- 데이터를 일정 단위로 쪼갠 덩어리
- Spring Batch에서 데이터 기반 처리 방식
- 읽기-처리-쓰기를 일정 크기로 나눈 데이터 덩어리 단위로 처리
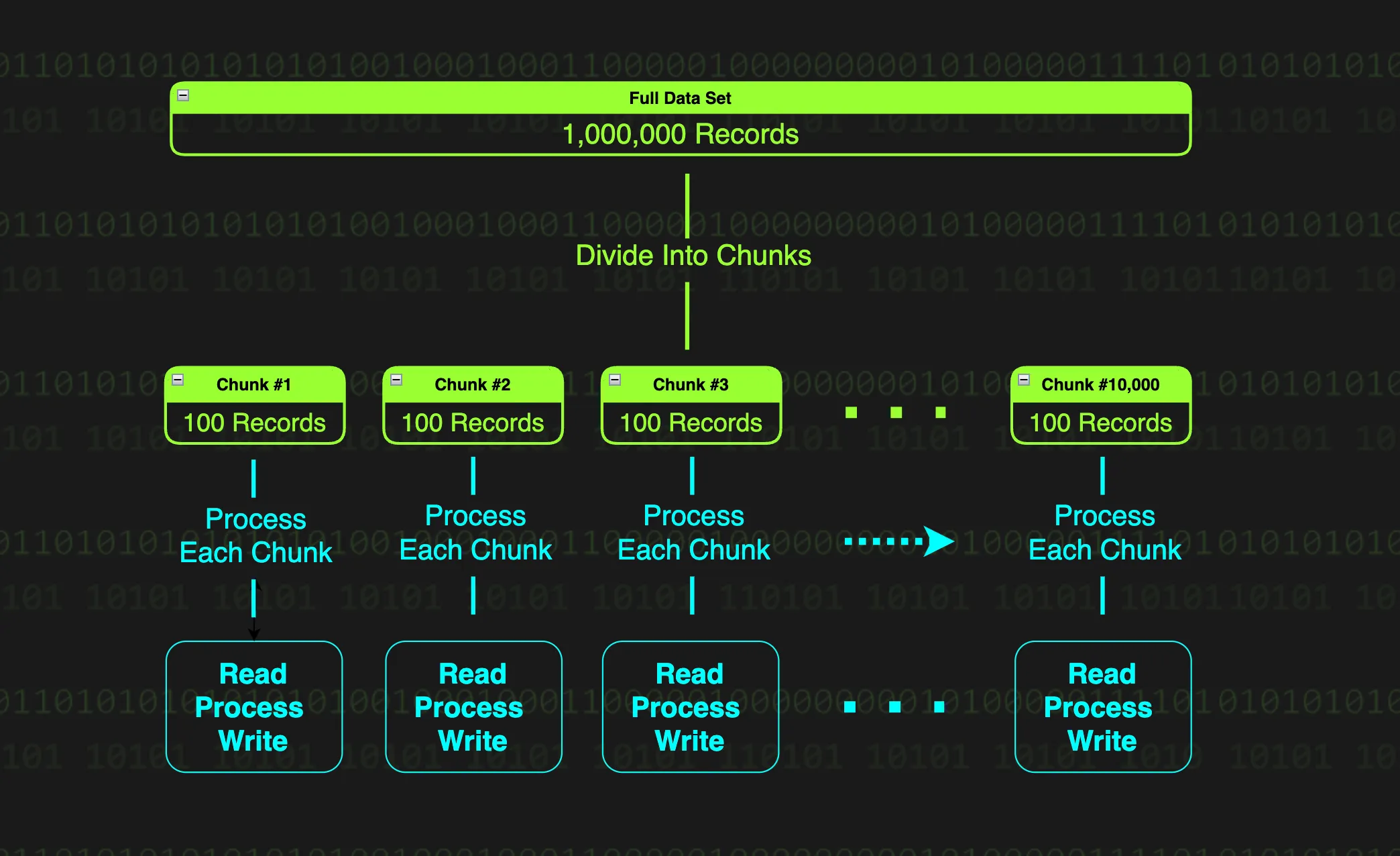
Chunk 사용 이유
- 메모리 보호: 대용량 데이터를 한 번에 처리하지 않고 청크 단위로 분할
- 가벼운 트랜잭션: 청크 단위로 트랜잭션 관리하여 실패 시 롤백 범위 최소화
- 복구 용이성: 이전 청크는 커밋 완료, 실패한 청크만 롤백 후 재시작
청크 지향 처리의 3대장
1. ItemReader - 데이터를 읽어오는 컴포넌트
public interface ItemReader<T> {
T read() throws Exception,
UnexpectedInputException,
ParseException,
NonTransientResourceException;
}- 한 번에 하나씩: read() 메서드가 아이템을 하나씩 반환
- null 반환 시 종료: 더 이상 읽을 데이터가 없으면 null 반환하여 Step 종료
- 다양한 구현체: FlatFileItemReader, JdbcCursorItemReader 등 제공
- 데이터 소스: 파일, 데이터베이스, 메시지 큐 등 다양한 소스 지원
2. ItemProcessor - 데이터를 가공하는 컴포넌트
public interface ItemProcessor<I, O> {
O process(I item) throws Exception;
}- 데이터 가공: 입력 데이터(I)를 원하는 형태(O)로 변환
- 필터링: null 반환 시 해당 데이터는 처리 흐름에서 제외
- 데이터 검증: 유효성 검사 후 예외 발생 가능
- 생략 가능: ItemProcessor 없이 ItemReader → ItemWriter 직접 연결 가능
- 비즈니스 로직: 원본 데이터를 비즈니스 로직에 맞게 가공하거나 출력 시스템이 요구하는 형식으로 변환
3. ItemWriter - 데이터를 저장하는 컴포넌트
public interface ItemWriter<T> {
void write(Chunk<? extends T> chunk) throws Exception;
}- 한 덩어리씩 처리: Chunk 단위로 묶어서 한 번에 데이터 처리
- 다양한 구현체: FlatFileItemWriter, JdbcBatchItemWriter 등 제공
- 저장 방식: DB에 INSERT, 파일에 WRITE, 메시지 큐에 PUSH 등
- 배치 처리: 한 건씩이 아닌 청크 단위로 묶어서 효율적으로 처리
청크 지향 처리 조립하기
@Bean
public Step processStep(JobRepository jobRepository, PlatformTransactionManager transactionManager) {
return new StepBuilder("processStep", jobRepository)
.<CustomerDetail, CustomerSummary>chunk(10, transactionManager) // 청크 지향 처리 활성화
.reader(itemReader()) // 데이터 읽기 담당
.processor(itemProcessor()) // 데이터 처리 담당
.writer(itemWriter()) // 데이터 쓰기 담당
.build();
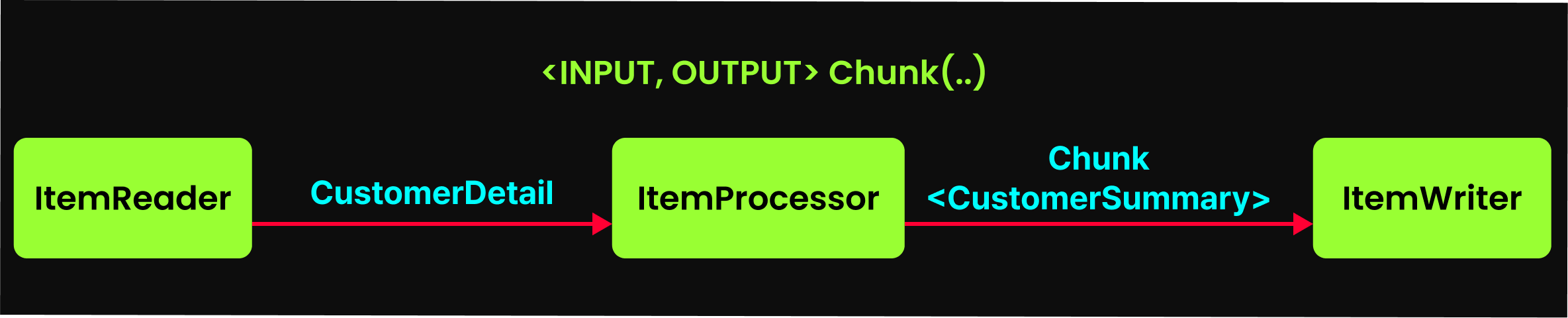
}구성 요소
- 청크 사이즈 지정:
.chunk(10, transactionManager)- 10개씩 묶어서 처리 - 제네릭 타입 정의:
<CustomerDetail, CustomerSummary>- 데이터 변환 흐름 정의 - 3대장 등록: reader(), processor(), writer() 메서드로 구현체 전달
청크 지향 처리의 흐름
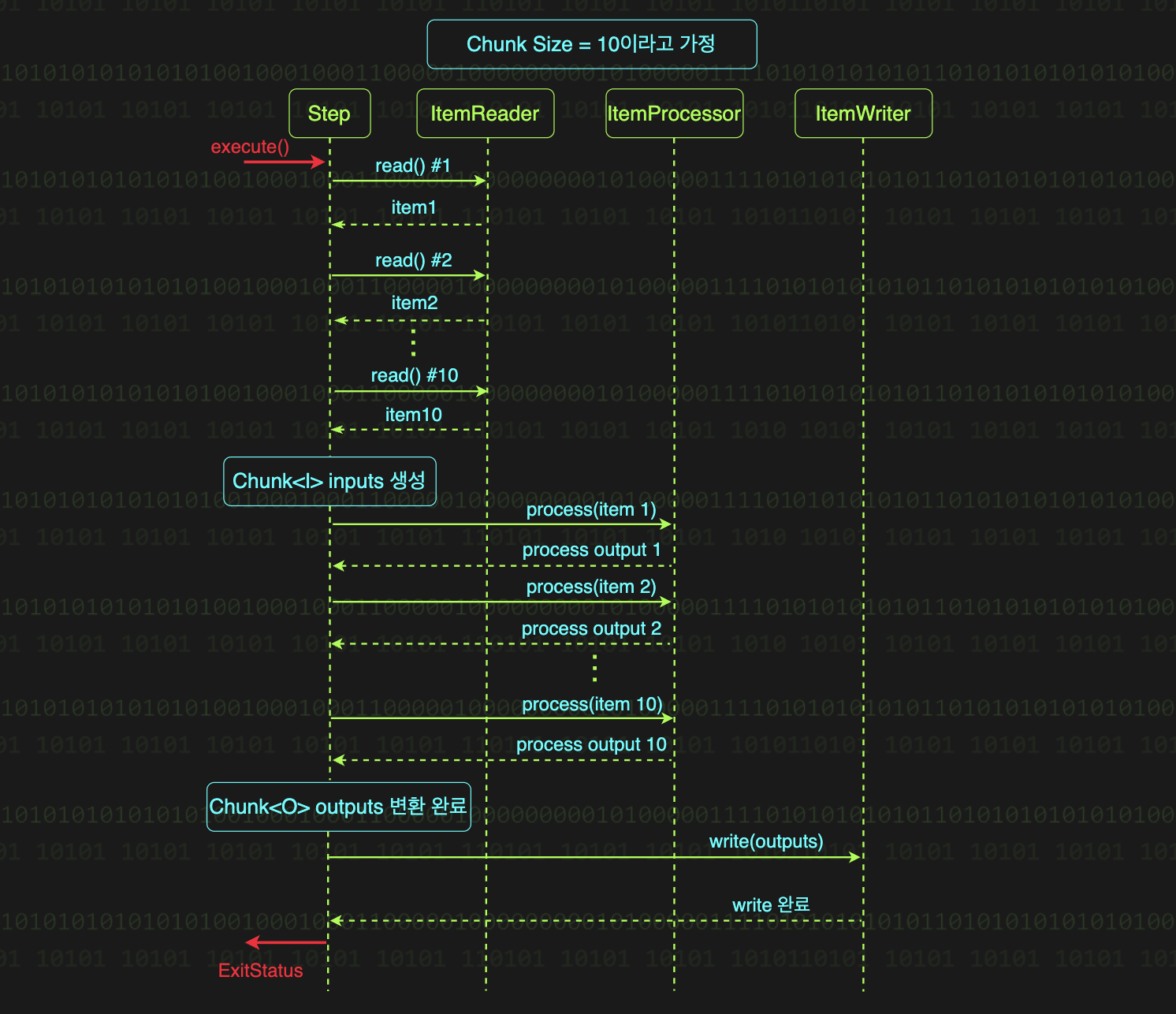
1. 데이터 읽기 (ItemReader)
- read() 메서드가 청크 크기만큼 호출되어 데이터 수집
- 청크 크기가 10이면 read()가 10번 호출
- 각 호출마다 하나의 아이템(파일의 한 줄, DB의 한 행)을 반환
- 더 이상 읽을 데이터가 없으면 null 반환하여 Step 종료
2. 데이터 가공 (ItemProcessor)
- 청크 내 각 아이템을 하나씩 처리
- process() 메서드가 청크 크기만큼 호출
- 청크 크기가 10이면 process()가 10번 호출
- 각 아이템을 입력받아 가공, 필터링, 검증 작업 수행
- null 반환 시 해당 아이템은 처리 흐름에서 제외
3. 데이터 쓰기 (ItemWriter)
- 청크 전체를 한 번에 처리
- write() 메서드에 Chunk 타입으로 전달
- 청크 내 모든 아이템을 묶어서 한 번에 저장/출력
- DB 배치 INSERT, 파일 배치 WRITE 등 효율적인 처리
청크 단위 반복의 종료 조건
- ItemReader의 null 반환: 더 이상 읽을 데이터가 없을 때
- 마지막 청크 처리: 청크 크기를 채우지 못해도 남은 데이터 처리 후 종료
예시: 97개 데이터를 청크 크기 10으로 처리
- 처음 9번의 반복: 각각 10개씩 처리 (총 90개)
- 마지막 10번째 반복:
- read() 호출 1~7번: 남은 7개 데이터 정상 읽기
- read() 호출 8번째: null 반환 (더 이상 읽을 데이터 없음)
- 7개 데이터로 청크 구성하여 처리
- Spring Batch가 마지막 반복 표시 확인 후 종료
청크 처리와 트랜잭션
- 청크 단위 트랜잭션: 각 청크 단위 반복마다 별도 트랜잭션 시작/커밋
- 안전한 복구: 이전 청크는 커밋 완료, 실패한 청크만 롤백
- 부분 재시작: 전체 데이터를 처음부터 다시 처리할 필요 없음
- 작은 실패: 100만 건을 하나의 트랜잭션으로 처리하면 오류 시 전체 롤백, 청크 단위로는 실패 범위 제한
적절한 청크 사이즈 선택
청크 사이즈가 클 때
- 메모리에 많은 데이터를 한 번에 로드
- 트랜잭션 경계가 커져서 롤백 시 데이터 손실 증가
- 대용량 데이터 처리 시 메모리 부족 가능성
청크 사이즈가 작을 때
- 트랜잭션 경계가 작아서 롤백 시 데이터 손실 최소화
- 읽기/쓰기 I/O가 자주 발생하여 성능 저하 가능
- 건당 10ms 소요되는 요청을 100만번 호출하면 약 2.77시간 소요
선택 기준
- 업무 요구사항: 데이터의 양과 처리 시간 요구사항
- 시스템 리소스: 메모리, CPU, 네트워크 대역폭
- 트레이드오프: 성능 vs 안정성, 메모리 vs I/O 빈도
- 실험적 접근: 다양한 청크 사이즈로 테스트하여 최적값 도출
청크 지향 처리 특징
- 대용량 데이터 처리에 적합: 메모리 효율적이고 안전한 처리
- 3대장 패턴: ItemReader, ItemProcessor, ItemWriter로 구성
- 완벽한 책임 분리: 각 컴포넌트가 독립적인 역할 수행
- 높은 재사용성: 컴포넌트들을 조합하여 다양한 배치 구성 가능
- Reader-Processor-Writer 패턴: 대용량 데이터를 처리하기 위한 최적의 아키텍처
- 변경에 강함: 요구사항 변경 시 해당 컴포넌트만 수정하면 됨
- 표준화된 구조: 데이터를 다루는 배치 작업의 표준 패턴
'Spring > Spring Batch' 카테고리의 다른 글
| Spring Batch 3. Spring Batch Listener (3) | 2025.08.15 |
|---|---|
| Spring Batch 2. JobParameter (0) | 2025.08.02 |