스키마 레지스트리
DB와 비슷하게 카프카에서도 스키마를 사용하는데, 토픽으로 전송되는 메시지에 대해 미리 스키마를 정의한 후 전송함으로써 DB에서 얻을 수 있는 동일한 효과를 얻음
10.1 스키마의 개념과 유용성
어떤 누가와도 쉽게 사용하고, 장애가 발생해도 쉽게 복구할 수 있어야함
명세서, 정의 등을 해야하는 데, 이것이 스키마
카프카의 데이터 흐름은 대부분 브로드캐스트 방식
카프카는 데이터를 전송하는 프로듀서를 일방적으로 신뢰할 수밖에 없는 방식
그러므로 프로듀서 관리자는 카프카 토픽의 데이터를 컨슘하는 관리자에게 반드시 데이터 구조를 설명해야함
데이터에 대한 정확한 정의와 의미를 알려주는 역할 -> 스키마
10.2 카프카와 스키마 레지스트리
카프카에서 스키마를 활용하는 방법과 스키마 레지스트리에 가장 최적화된 에이브로 활용에 대해 알아볼 것
10.2.1 스키마 레지스트리 개요
카프카에서 스키마를 활용하는 방법은 스키마 레지스트리라는 별도 애플리케이션을 이용하는 것
스키마 레지스트리란? 글자 그대로 스키마를 등록하고 관리하는 애플리케이션
스키마 레지스트리 구성도
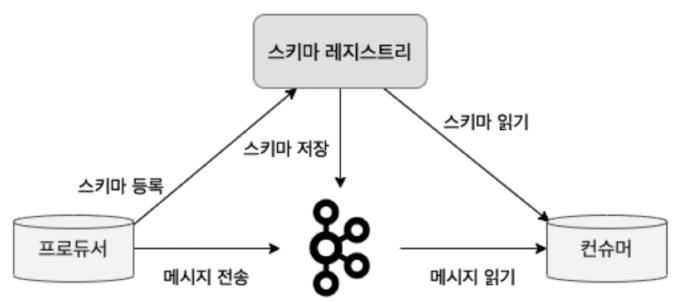
스키마 레지스트리는 카프카와 별도로 구성된 독립적 애플레킹션
카프카로 메시지를 전송하는 프로듀서와 직접 통신하며 카프카로부터 메시지를 꺼내오는 컨슈머와도 직접 통신
클라이언트들이 스키마 정보를 사용하기 위해서는 프로듀서와 컨슈머, 스키마 레지스트리간에 직접 통신이 이루어져야함
프로듀서는 스키마 레지스트리에 스키마를 등록, 스키마 레지스트리는 프로듀서에 의해 등록된 스키마 정보를 내부 토픽에 저장
프로듀서는 스키마 레지스트리에 등록된 스키마 ID와 메시지를 카프카로 전송
컨슈머는 스키마 ID를 스키마 레지스트리로부터 읽어온 후 프로듀서가 전송한 스키마 ID와 메시지를 조합해 읽을 수 있음
스키마 레지스트리를 이용하기 위해 스키마 레지스트리가 지원하는 데이터 포맷을 사용해야하는 데 가장 대표적인 포맷은 에이브로
10.2.2 스키마 레지스트리의 에이브로 지원
시스템, 프로그래밍 언어, 프로세싱 프레임워크 사이에서 데이토 교환을 도와주는 오픈소스 직렬화 시스템
빠른 바이너리 데이터 포멧을 지원하며 JSON 형태의 스키마를 정의할 수 있는 간결한 데이터 포맷
에이브로는 바이너리 형태이고, JSON과 매핑되며, JSON은 메시지마다 필드 네임들이 포함되 비효율적이므로 에이브로를 권장
에이브로는 JSON과 달리 데이터 필드마다 데이터 타입을 정의할 수 있고 doc를 이용해 각 필드의 의미를 데이터를 사용하고자 하는 사용자들에게 정확히 전달
doc 기능을 활용하면 데이터 필드를 정의한 엑셀 문서나 위키 페이지등 문서 공유 필요가 없어짐
10.2.3 스키마 레지스트리 설치
카프카 클러스터 설정 초기화
cd kafka2
cd chapter2/ansible_playbook
ansible_playbook -i hosts kafka.ymlzookleeper.yml을 이용해 주키퍼 설치, kafka.yml을 이용해 카프카 설치
한 번에 설치하려면 site.yml 사용
ansible_playbook -i hosts site.yml스키마 레지스트리 파일 다운로드
원래는 카프카와 스키마 레지스트리를 분리해야하지만 여기선 그냥 진행
sudo wget http://packages.confluent.io/archive/6.1/ confluent-community-6.1.0.tar.gz -0 /opt/confluent-community-6.1.0.tar.gz
sudo tar zxf /opt/confluent-community-6.1.0.tar.gz -C /usr/local/
sudo ln -s /usr/local/confluent-6.1.0 /usr/local/confluent스키마 레지스트리 설정 시작
vi /usr/local/confluent/etc/schema-registry/schema-registry.properties스키마 레지스트리 옵션 설정
listeners=http://0.0.0.0:8081 # 스키마 레지스트레 포트 8081 설정
kafkastore.bootstrap.servers=PLAINTEXT://peter-kafka01.f00.bar:9092,peter-kafka02.
foo.bar:9092,peter-kafka03.foo.bar:9092 # 스키마의 버전 히스토리 및 관련 데이터를 저장할 카프카 주소 입력
kafkastore.topic=_schemas # 스키마의 버전 히스토리 및 관련 데이터 저장 포틱의 이름을 _schemas로 지정
schema.compatibility.level=full # 스키마 호환성 레벨을 full로 설정스키마 저장과 관리 목적으로 카프카 토픽을 사용하는 것과 스키마 호환성 레벨을 반드시 숙지
브로커의 _schemas 토픽이 스키마 레지스트리의 저장소로 활용, 모든 스키마의 제목, 버전, ID 등이 저장됨
스키마 관리 목적으로 사용하는 메시지들은 순서가 중요하기 떄문에 _schemas 토픽의 파티션 수는 항상 1
스키마 레지스트리 실행
스키마 레지스트리 API
| 옵션 | 설명 |
|---|---|
| GET /schemas | 현재 스키마 레지스트리에 등록된 전체 스키마 리스트 조회 |
| GET /schemas/ids/id | 스키마 ID로 조회 |
| GET /schemas/ids/id/versions | 스키마 ID의 버전 |
| GET /subjects | 스키마 레지스트리에 등록된 subject 리스트 조회 subject는 토픽이름=key, 토픽이름=value 형태로 쓰임 |
| GET /subjects/서브젝트 이름/versions | 특정 서브젝트의 버전 리스트 조회 |
| GET /config | 전역으로 설정된 호환성 레벨 조회 |
| GET /config/서브젝트 이름 | 서브젝트에 설정된 호환성 조회 |
| DELETE /subjects/서브젝트 이름 | 특정 서브젝트 전체 삭제 |
| DELETE /subjects/서브젝트 이름/versions/버전 | 특정 서브젝트에서 특정 버전만 삭제 |
10.3 스키마 레지스트리 실습 338
10.3.1 스키마 레지스트리와 클라이언트 동작
카프카의 모델은 펍/섭 모델로 프로듀서와 컨슈머는 직접 통신을 주고받지 않음
스키마 레지스트리와 클라이언트 동작
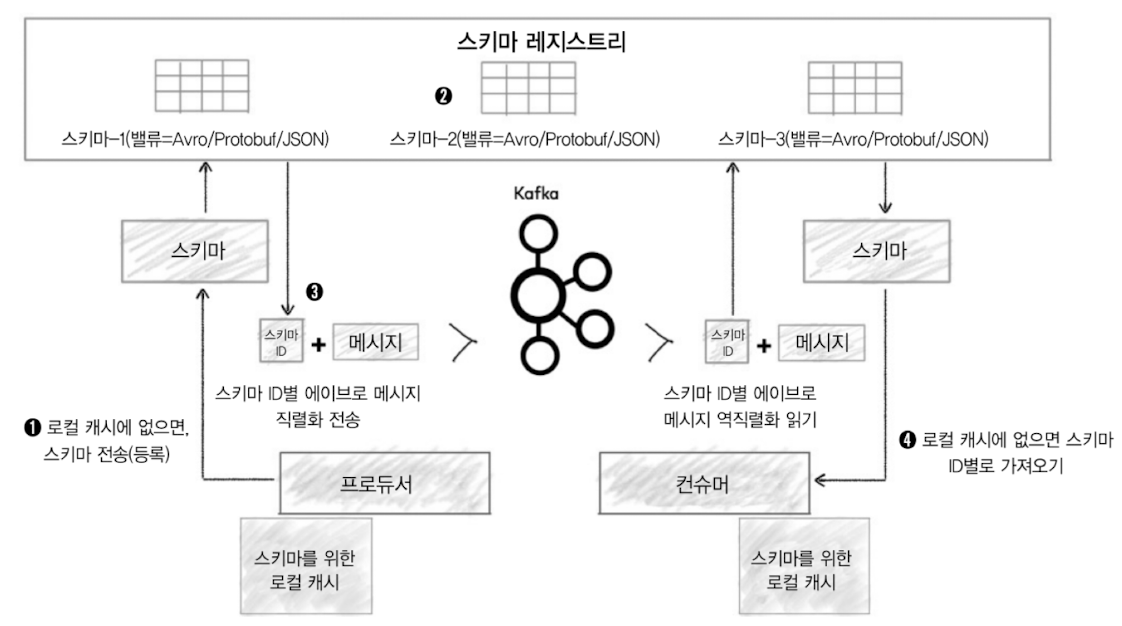
1: 에이브로 프로듀서는 컨플루언트에서 제공하는 io.confluent.kafka.serializers.KafkaAvroSerializer라는 새로운 직렬화를 사용해 스키마 레지스트리의 스키마가 유효한지 여부를 확인
만약 확인되지 않으면 에이브로 프로듀서는 스키마를 등록하고 캐시
2: 스키마 레지스트리는 현 스키마가 저장소에 저장된 스키마와 동일한 것인지, 진화한 스키마인지 확인
스키마 레지스트리 자체적으로 각 스키마에 대해 고유 ID를 할당. 이 ID는 순차적으로 1씩 증가하지만 반드시 연속적이지는 않음
스키마에 문제가 없다면 스키마 레지스트리는 프로듀서에게 고유 ID를 응답
3: 프로듀서는 스키마 레지스트리로부터 받은 스키마 ID를 참고해 메시지를 카프카로 전송
프로듀서는 스키마의 전체 내용이 아닌 메시지와 스키마 ID만 전송
4: 에이브로 컨슈머는 스키마 ID로 컨플루언트에서 제공하는 io.confluent.kafka. serializers.KafkaAvroDeserializer라는 새로운 역직렬화를 사용해 카프카의 토픽에 저장된 메시지를 읽음
이때 컨슈머가 스키마 ID를 갖고 있지 않다면 스키마 레지스트리로부터 가져옴
프로듀서와 컨슈머는 직접 스키마를 주고받는 등 통신을 하지 않지만 각자 스키마 레지스트리와 통신하며 스키마의 정보를 주고받음
프로듀서가 스키마 정보를 스키마 레지스트리에 등록함으로써 프로듀서가 전송하는 메시지의 크기를 줄일 수 있고 컨슈머가 읽는 메시지의 크기도 줄일 수 있음
10.4 스키마 레지스트리 호환성
스키마 레지스트리는 버전별 스키마에 대한 관리를 효율적으로 해주며, 각 스키마에 대해 고유한 ID와 버전 정보를 관리
스키마 레지스트리에서는 하나의 서브젝트에 대한 버전 정보별로 진화하는 각 스키마를 관리해줌
스키마가 진화함에 따라 호환성 레벨을 검사해야 하는데, 스키마 레지스트리에서는 대표적으로 BACKWARD, FORWARD, FULL 호환성 레벨 제공
10.4.1 BACKWARD 호환성
진화된 스키마를 적용한 컨슈머가 진화 전의 스키마가 적용된 프로듀서가 보낸 메시지를 읽을 수 있도록 허용하는 호환성
BACKWARD 호환성
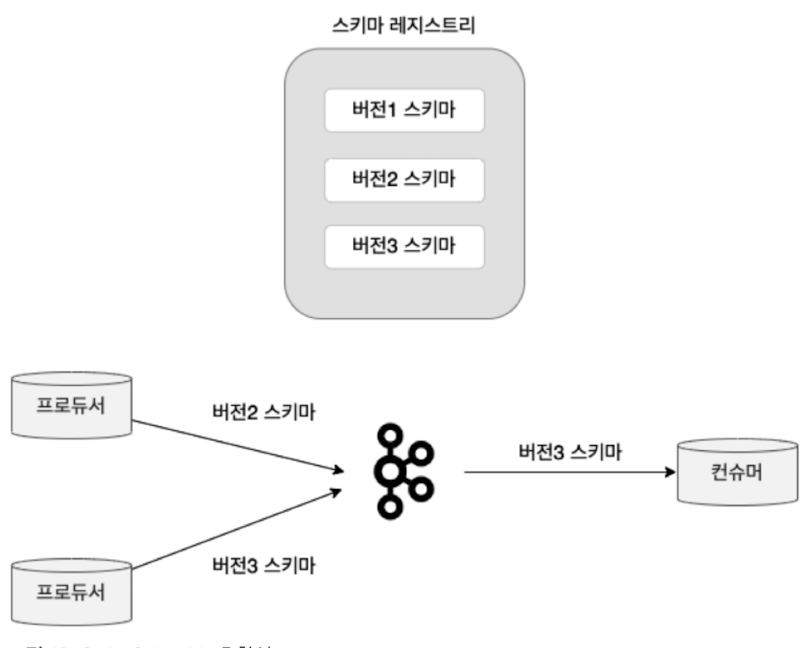
위 상태일 때, 최신 버전의 스키마인 버전3 스키마를 이용해 컨슈머가 데이터를 가져올 때, 컨슈머는 자신과 동일한 버전인 버전3 스키마를 사용하는 프로듀서의 메시지를 처리할 수 있음
스키마의 버전 업데이트가 필요하다면 프로듀서와 컨슈머의 스키마도 업데이트해줘야 하는데, BACKWARD 호환성에서는 먼저 상위 버전의 스키마를 컨슈머에게 적용하고 난 뒤에 프로듀서에게 상위 버전의 스키마를 적용해야 함
만약 모든 하위 버전의 스키마를 호환하고 싶다면 호환성 타입을 BACKWARD가 아닌 BACKWARD_TRANSITIVE로 설정해야 함
BACKWARD 요약 정리
| 호환성 레벨 | 지원 버전(컨슈머 기준) | 변경 허용 항목 | 스키마 업데이트 순서 |
|---|---|---|---|
| BACKWARD | 자신과 동일한 버전과 하나 아래의 하위 버전 (예: 버전3으로 버전2도 처리 가능) |
필드 삭제, 기본값이 지정된 필드 추가 | 컨슈머 -> 프로듀서 |
| BACKWARD_TRANSITIVE | 자신과 동일한 버전을 포함한 모든 하위 버전 (예: 버전3으로 버전2, 버전1 처리 가능) |
필드 삭제, 기본값이 지정된 필드 추가 | 컨슈머 -> 프로듀서 |
10.4.2 FORWARD 호환성
BACKWARD와 대비되는 성질을 지니며 진화된 스키마가 적용된 프로듀서가 보낸 메시지를 진화 전의 스키마가 적용된 커늇머가 읽을 수 있게 하는 호환성을 말함
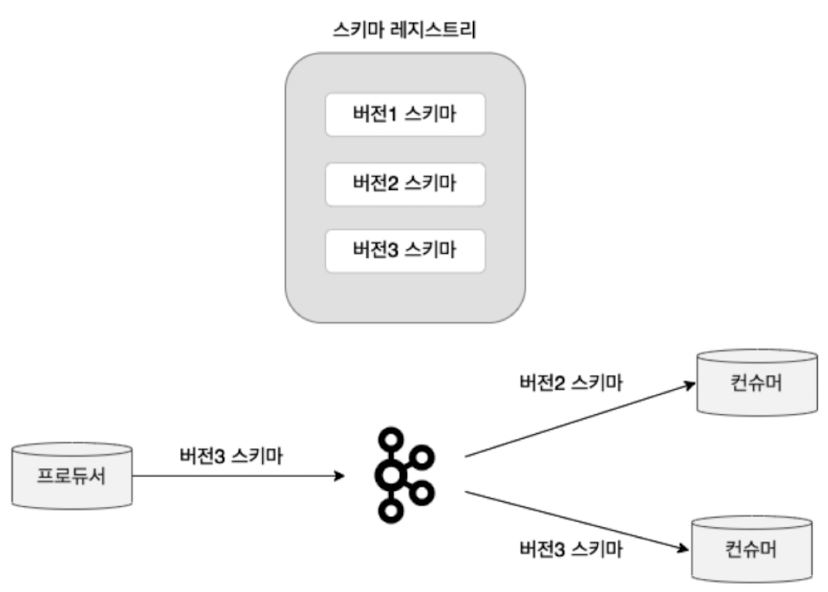
FORWARD는 상위 버전 스키마를 먼저 프로듀서에게 적용한 다음, 컨슈머에게 적용함
만약 모든 버전으 ㅣ스키마를 호환하고자 한다면 호환성 타입을 FORWARD가 아닌 FORWARD_TRANSITIVE로 설정해야 함
FORWARD 요약 정리
| 호환성 레벨 | 지원 버전(컨슈머 기준) | 변경 허용 항목 | 스키마 업데이트 순서 |
|---|---|---|---|
| FORWARD | 자신과 동일한 버전과 하나 위의 상위 버전 (예: 버전2로 버전3도 처리 가능) |
필드 추가, 기본값이 지정된 필드 삭제 | 프로듀서 -> 컨슈머 |
| FORWARD_TRANSITIVE | 자신과 동일한 버전을 포함한 모든 상위 버전 (예: 버전2로 버전3과 그 이상 처리 가능) |
필드 추가, 기본값이 지정된 필드 삭제 | 프로듀서 -> 컨슈머 |
10.4.3 FULL 호환성
BACKWARD, FORWARD 모두 지원
스키마가 진화함에 따라 프로듀서 측면과 컨슈머 측면 양쪽에서 호환되므로 더 편리하게 사용할 수 있음
BACKWARD, FORWARD와 동일하게 최근 2개 버전의 스키마를 지원, 모든 버전의 스키마를 호환하고 싶다면 FULL_TRANSITIVE로 설정해야 함
FULL 호환성 요약 정리
| 호환성 레벨 | 지원 버전(컨슈머 기준) | 변경 허용 항목 | 스키마 업데이트 순서 |
|---|---|---|---|
| FULL | 자신과 동일한 버전과 하나 위 또는 하나 아래 버전 (예: 버전2로 버전1 또는 버전3 처리 가능) |
기본값이 지정된 필드 추가, 기본값이 지정된 필드 삭제 | 순서 상관없음 |
| FULL_TRANSITIVE | 자신과 동일한 버전을 포함한 모든 상위 버전과 하위 버전 (예: 버전 번호 무관하게 모든 버전 처리 가능) |
기본값이 지정된 필드 추가, 기본값이 지정된 필드 삭제 | 순서 상관없음 |
'Message Queue > Kafka' 카테고리의 다른 글
| 실전 Kafka 개발부터 운영까지. 11장 카프카 커넥트 (0) | 2024.06.27 |
|---|---|
| 실전 Kafka 개발부터 운영까지. 9장 카프카 보안 (0) | 2024.06.10 |
| 실전 Kafka 개발부터 운영까지. 8장 카프카 버전 업그레이드와 확장 (0) | 2024.06.10 |
| 실전 Kafka 개발부터 운영까지. 7장 카프카 운영과 모니터링 (0) | 2024.04.24 |
| 실전 Kafka 개발부터 운영까지. 6장 컨슈머의 내부 동작 원리와 구현 (0) | 2024.04.22 |