카프카 커넥트
카프카 커넥트는 아파치 카프카의 오픈소스 프로젝트
데이터베이스 같은 외부 시스템과 카프카를 쉽게 연결하기 위한 프레임워크
REST API로 구성되어있음
커넥트 프레임워크를 이용해 대용량의 데이터를 카프카의 안팎으로 쉽게 이동시킬 수 있음
프로듀서와 컨슈머를 직접 개발해 원하는 동작을 실행할 수 있지만, 카프카 커넥트를 이용하면 더 효율적으로 빠르게 구성하고 적용시킬 수 있음
카프카 커넥트 장점
데이터 중심 파이프라인
커넥트를 이용해 카프카로 데이터를 송수신
유연성과 확장성
테스트 및 일회성 작업을 위한 단독 모드로 실행할 수 있고, 대규모 운영환경을 위한 분산 모드(클러스터)로 실행할 수 있음
재사용성과 기능 확장
커넥터는 이미 만들어진 기존 커넥터들을 활용할 수 있고 운영 환경에서의 요구사항에 맞춰 빠르게 확장이 가능함
손쉬운 확장을 통해 오버헤드를 낮춤
장애 및 복구
카프카 커넥트를 분산 모드로 실행하ㅏ여 노드의 장애 상황에 유연하게 대응 가능하므로 고가용성이 보장됨
11.1 카프카 커넥트의 핵심 개념
카프카 커넥트 구성도
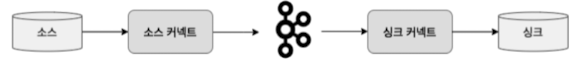
카프카 커넥트는 카프카 클러스터를 먼저 구성한 후 카프카 클러스터의 양쪽 옆에 배치할 수 있음
카프카를 기준으로 들어오고 나가는 양방향에 커넥트가 존재함.
동일한 두 커넥트를 서로 구분하기 위해 소스 방향에 있는 커넥트를 소스 커넥트, 싱크 방향에 있는 커넥트를 싱크 커넥트라고 함
카프카에 비교하면 소스와 카프카 사이에 위치해 프로듀서의 역할을 하는 것이 소스 커텍트, 카프카와 싱크 사이에 위치해 컨슈머 역할을 하는 것이 싱크 커넥트
카프카 커넥트 상세 구성도
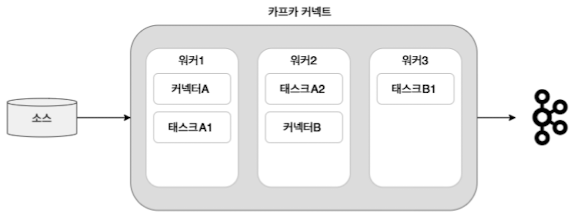
워커는 카프카 커넥트 프로세스가 실행되는 서버 또는 인스턴스 등을 의미하며 커넥트나 태스크들이 워커에서 실행됨
분산 모드는 특정 워커에 장애가 발생해도 해당 워커에서 동작 중인 커넥터나 태스크들이 다른 워커로 이동해 연속해서 동작할 수 있음, 단도 모드는 그렇지 않음
커넥터
커넥터는 직접 데이터를 복사하지 않고 데이터를 어디에서 어디로 복사해야 하는지의 작업을 정의하고 관리하는 역할
커넥트와 동일하게 소스에서 카프카로 전송하는 역할을 하는 소스 커넥터와 카프카에서 저장소로 싱크하는 싱크 커넥터가 있음
만약 관계형 DB 데이터를 카프카로 전송하고 싶다면 JDBC 소스 커넥터가 필요하고 카프카에 적재된 데이터를 HDFS로 적재하고자 하나다면 HDFS 싱크 커넥터가 필요함
태스크
태스크는 커넥터가 ㅏ정의한 작업을 직접 수행하는 역할
커넥터는 데이터 전송에 관한 작업을 정의한 후 각 태스크들을 워커에 분산함
그런 다음 워커에 분산 배치된 태스크들은 커넥터가 정의한 작업대로 데이터를 복사함
태스크 역시 소스 태스크와 싱크 태스크로 나뉨
약간 커넥터는 타겟 그룹, 태스크는 실행되는 인스턴스라고 생각
11.2 카프카 커넥트의 내부 동작
분산 배치된 각 태스크들은 메시지들을 소스에서 카파ㅡ카로 혹은 카프카에서 싱크로 이동시킴
이때 커넥트는 파티셔닝 개념을 적용해 데이터들을 하위 집합으로 나눔
카프카에서도 병렬 처리를 위해 토픽을 파티션으로 나누는데 커넥터도 이와 동일
주의
커넥트에서 나눈 파티션과 토픽의 파티션은 용어만 같고 아무 관계가 없음
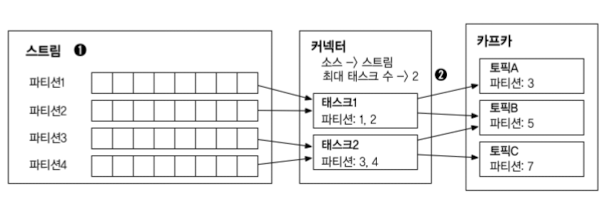
커넥터에서 복사되어야하는 데이터들은 레코드들의 순서에 맞추어 파티셔닝되어야 함
그림에서 스트림 영역으로 표시된 부분이 데이터가 파티셔닝된 것을 나타냄
커넥터에 정의된 값을 살펴보면 최대 태스크 수는 2로 정의되어 있음
스트림에서 나뉜 각 파티션들은 2개의 태스크에 할당되고, 태스ㅡ크들은 실제로 데이터를 이동하는 동작을 처리함
각 파티션들에는 오프셋도 함께 포함되어 있어 커넥트의 장애나 실패가 발생할 경우 지정된 위치부터 데이터를 이동시킬 수 있음
커넥터의 따라 오프셋의 기준이 달라질 수 있는데, 일반적인 파일을 전송하는 커넥터일 경우에는 오프셋이 파일의 위치를 나타내며 DB의 경우에는 타임스탬프나 시퀀스 ID를 나타냄
11.3 단독 모드 카프카 커넥트
카프카 컼넥트는 카프카 설치 파일 안에 패키징되어 있으므로 별도로 설치하지 않아도 됨
11.3.1 파일 소스 커넥터 실행

로컬 디렉토리에 test.txt 파일을 생성 후 파일 소스 커넥터를 실행하면 파일 소스 커넥터는 로컬의 test.txt 파일 내용을 읽어 카프카의 connect-test라는 토픽으로 메시지를 전송함
파일 싱크 커넥터는 connect-tet 토픽에서 메시지를 읽은 뒤 해당 내용을 로컬의 test.sink.txt 파일로 저장함
소스 파일 커넥터 수정
connect-file-source.properties
# 커넥터에서 실벽하는 이름
name=local-file-source
# 커넥터에서 사용하는 클래스
connector.class=FileStreamSource
# 실제 작업을 처리하는 태스크의 최대 수
tasks.max=1
# 파일 소스 커넥터가 읽을 파일 지정
file=/home/ec2-user/test.txt
# 파일 소스 커넥터가 읽은 내용을 카프카의 connect-test 토픽으로 전송
topic=connect-testconnect-standalone.properties
# 브로커 주소
bootstrap.servers=localhost:9092
# 카프카로 데이터를 보내거나 가져올 때 사용하는 포맷을 지정, 키와 밸류를 각각 지정
key.converter=org.apache.kafka.connect.json.JsonConverter
value.converter=org.apache.kafka.connect.json.JsonConverter
# 스키마가 포함된 구조를 사용
key.converter.schemas.enable=false
value.converter.schemas.enable=false
# 재처리 등을 목적으로 오프셋을 파일로 지정
offset.storage.file.filename=/tmp/connect.offsets
# 오프셋 플러시 주기를 설정
offset.flush.interval.ms=1000011.3.2 파일 싱크 커넥터 실행
파일 소스 커넥터는 설정 파일을 로드하면서 실행했지만 카프카 카프카 커넥트의 REST API를 이용해 실행할 수 있음
[ec2-user@ip-172-31-5-59 ~]$ curl --header "Content-Type: application/json" --header
"Accept: application/json" --request PUT --data '{
"name": "local-file-sink",
"connector.class": "FileStreamSink",
"tasks.max": "1",
"file": "/home/ec2-user/test.sink.txt",
"topics": "connect-test"
}' http://localhost:8083/connectors/local-file-sink/config역할은 위와 동일

카프카 커넥트 REST API
| API 옵션 | 설명 |
|---|---|
| GET / | 커넥트의 버전과 클러스터 ID 확인 |
| GET /connectors | 커넥터 리스트 확인 |
| GET /connectors/커넥터 이름 | 커넥터 이름의 상세 내용 확인 |
| GET /connectors/커넥터 이름/config | 커넥터 이름의 config 정보 확인 |
| GET /connectors/커넥터 이름/status | 커넥터 이름의 상태 확인 |
| PUT /connectors/커넥터 이름/config | 커넥터 config 설정 |
| PUT /connectors/커넥터 이름/pause | 커넥터의 일시 중지 |
| PUT /connectors/커넥터 이름/resume | 커넥터의 다시 시작 |
| DELETE /connectors/커넥터 이름 | 커넥터의 삭제 |
| GET /connectors/커넥터 이름/tasks | 커넥터의 태스크 정보 확인 |
| GET /connectors/커넥터 이름/tasks/태스크 ID/status | 커넥터에서 특정 태스크의 상태 확인 |
| POST /connectors/커넥터 이름/tasks/태스크 ID/restart | 커넥터에서 특정 태스크 재시작 |
11.4 분산 모드 카프카 커넥트
운영환경에서는 단독 모드보다 분산 모드를 사용해야함
다양한 차이가 있지만 메타 정보의 저장소 위치가 다른 것이 가장 큰 특징
카프카 내부 토피을 이용하는 방법은 컨슈머 그룹들의 오프셋 정보를 __consumer_offsets 토픽에 저장하는 방법과 유사
장애가 났을 때 다른 워커가 알 수 있도록 안전한 저장소인 카프카 내부 토픽을 메타 저장소로 이용
카프카 커넥트에서 사용하는 토픽들은 커넥트 운영에서 중요한 정보가 저장되어있으므로 리플리케이션 팩터 수는 반드시 3으로 설정해야 함
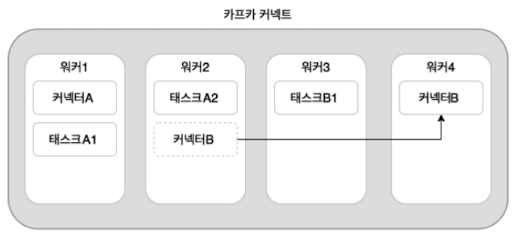
자동리밸런싱은 워커들 안에서 태스크와 커넥터가 최대한 균등하게 배치될 수 있게 함
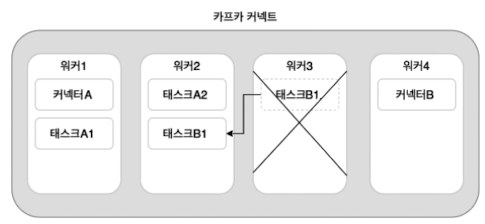
카프카 커넥트를 분산 모드로 실행하려면 장애 대응 및 리밸런싱 동작 등을 위해 최소 2개 이상의 워커로 구성해야함
카프카 커넥트 분산 모드 설정 파일
connect-distributed.properties
bootstrap.servers=peter-kafka01.foo.bar:9092,peter-kafka02. foo.bar:9092,peter-
kafka03.foo.bar :9092
group.id=peter-connect-cluster
key.converter=org.apache.kafka.connect.converters.ByteArrayConverter value.converter=org.apache.kafka.connect.converters.ByteArrayConverter
key.converter.schemas.enable=false value.converter.schemas.enable=false offset.storage. topic=connect-offsets
offset.storage.replication.factor=3
offset.storage.partitions=25
config.storage. topic=connect-configs 7
config.storage.replication.factor=3
config.storage.partitions=1
status.storage. topic=connect-status status.storage.replication.factor=3
status.storage.partitions=5
offset.flush.interval.ms=1000011.5 커넥터 기반의 미러 메이커 2.0
주요 개념:
- 다중 클러스터 활용: 기업에서는 여러 개의 카프카 클러스터를 사용하는 경우가 많음. 장애 복구 차원에서 다중 데이터 센터 운영 등 다양한 시나리오에서 사용됨
- 리플리케이션 필요성: 온프레미스에서 클라우드로의 데이터 마이그레이션, 데이터 분석 용도 등에서 카프카 간의 리플리케이션 필요함
- 미러 메이커 도구: 아파치 카프카는 미러 메이커라는 도구를 통해 카프카 간 리플리케이션을 제공함
미러 메이커 1.0의 한계:
- 간단한 컨슈머와 프로듀서 기반 도구로, 엔터프라이즈 환경에 필요한 추가 기능이 부족.
- 원격 토픽 생성 시 소스 토픽의 옵션을 적용할 수 없고, 설정 변경이 어려움.
미러 메이커 2.0의 개선:
- 미러 메이커 2.0은 커넥터 프레임워크 기반으로, 설정이 쉽고 확장 가능.
- 엔터프라이즈 환경에 맞춘 기능과 확장성 제공.
기업에서는 여러 카프카 클러스터를 활용하여 데이터 복구 및 분석을 위한 리플리케이션을 설정하는 경우가 많음
초기 버전의 미러 메이커는 이러한 엔터프라이즈 요구를 충족시키기 어렵지만, 미러 메이커 2.0은 커넥터 기반 프레임워크로서 이러한 문제를 해결하고 설정과 확장성을 크게 개선함
원격 토픽과 에일리어스 기능
미러 메이커 2.0의 리플리케이션 방식:
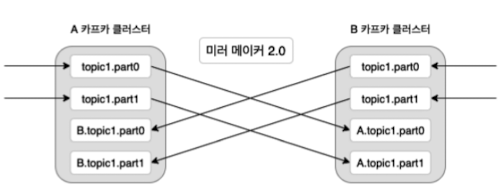
- 단방향 및 양방향 리플리케이션: 소스 클러스터에서 타겟 클러스터로의 단방향 리플리케이션뿐만 아니라, 양방향 리플리케이션도 가능함. 이를 통해 데이터가 두 클러스터 간에 상호 복제될 수 있음
- 액티브/액티브 리플리케이션: 기본적으로 액티브/액티브 리플리케이션 방식이 적용되어, 서로의 리플리케이션이 병합되거나 순서가 뒤바뀌는 문제를 방지함
에일리어스 기능:
- 토픽 이름의 충돌 방지: 동일한 토픽명이 양쪽 클러스터에 존재하는 경우, 에일리어스를 사용해 토픽 이름을 구분할 수 있음. 예를 들어, A 클러스터의 topic1.part0는 B 클러스터의 Atopic1.part0로, B 클러스터의 topic1.part0는 A 클러스터의 Btopic1.part0로 복제됨
- 복잡한 토픽 이름 관리: 이를 통해 동일한 토픽명을 가지는 경우에도 문제 없이 양방향 리플리케이션을 수행할 수 있음
주요 개선 사항:
- 단방향 리플리케이션의 한계 해결: 미러 메이커 1.0에서는 동일한 토픽명으로 인해 혼란이 발생할 수 있었으나, 2.0에서는 에일리어스를 통해 이러한 문제를 해결함
- KIP-382 제안: KIP-382는 미러 메이커 2.0의 개선 사항을 제안하는 문서로, 양방향 리플리케이션을 포함한 다양한 개선점을 다룸
카프카 클러스터 통합
다중 클러스터 통합: 미러 메이커 2.0을 통해 여러 카프카 클러스터에서 토픽을 통합하여 하나의 다운스트림 컨슈머가 사용할 수 있습니다. 예를 들어, us-west1 클러스터의 us-west.topic1, us-east1 클러스터의 us-east.topic1, us-central1 클러스터의 us-central.topic1을 하나의 토픽으로 통합할 수 있음
토픽 병합: 토픽 이름이 다르더라도 데이터를 처리하는 형대로 병합하여 전달할 수 있으며, 필요에 따라 하나의 토픽으로 병합할 수 있음
무한 루프 방지
이중 클러스터 리플리케이션: 미러 메이커 2.0에서는 두 개의 클러스터 간 리플리케이션 설정을 통해 무한 루프를 방지할 수 있음.
에일리어스 기능을 통해 동일한 토픽명이 있는 경우에도 충돌을 방지함
토픽 설정 동기화
소스 토픽 설정 반영: 미러 메이커 2.0은 소스 토픽의 설정 변경 사항을 대상 토픽으로 자동으로 전파합니다. 예를 들어, 소스 토픽의 파티션 수가 증가하면 대상 토픽의 파티션 수도 증가함
안전한 저장소로 내부 토픽 활용
정상 상태 점검: 미러 메이커 2.0은 내부적으로 관련 데이터를 안전한 저장소에 저장하고, 정상 상태 점검을 수행하여 데이터를 보호합니다. 하트비트, 체크포인트 등의 정보를 내부 토픽에 저장하여 관리
카프카 커넥트 지원
미러 메이커 2.0의 특징:
- 성능, 신뢰성, 확장성 향상: 카프카 커넥트 프레임워크를 기반으로 하여 성능, 신뢰성, 확장성이 높아짐.
- 소스 및 싱크 커넥터 지원: 카프카 커넥트를 통해 소스 커넥터와 싱크 커넥터를 지원함으로써 다양한 데이터 소스와 싱크를 연결할 수 있음.
미러 메이커 2.0의 실행 방법:
- 전용 미러 메이커 클러스터 사용: 독립된 클러스터에서 미러 메이커를 실행.
- 분산 커넥트 클러스터에서 사용: 기존 분산 커넥트 클러스터에서 미러 메이커 커넥터를 이용.
- 독립형 커넥트 워커 사용: 독립형 커넥트 워커에서 실행.
- 레거시 방식의 스크립트 사용: 기존의 스크립트 방식으로 실행.
미러 메이커 2.0 구성도
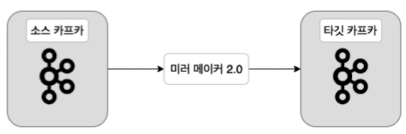
소스 카프카와 타겟 카프카 간에 미러 메이커 2.0을 통해 데이터 리플리케이션을 수행.
- 소스 카프카는 src로, 타겟 카프카는 dest로 지정하여 데이터를 복제함.
'Message Queue > Kafka' 카테고리의 다른 글
| 실전 Kafka 개발부터 운영까지. 10장 스키마 레지스트리 (0) | 2024.06.21 |
|---|---|
| 실전 Kafka 개발부터 운영까지. 9장 카프카 보안 (0) | 2024.06.10 |
| 실전 Kafka 개발부터 운영까지. 8장 카프카 버전 업그레이드와 확장 (0) | 2024.06.10 |
| 실전 Kafka 개발부터 운영까지. 7장 카프카 운영과 모니터링 (0) | 2024.04.24 |
| 실전 Kafka 개발부터 운영까지. 6장 컨슈머의 내부 동작 원리와 구현 (0) | 2024.04.22 |